正文
今天来完成任务一的实验十:提取下列用户特征,完成模型训练,并在阿里云天池平台提交结果:1、领券数、2、领券并消费数、3、领券未消费数、4、 领券并消费数 / 领券数、5、领取并消费优惠券的平均折扣率、6、领取并消费优惠券的平均距离、7、在多少不同商家领取并消费优惠券、8、在多少不同商家领取优惠券、9、在多少不同商家领取并消费优惠券 / 在多少不同商家领取优惠券
其实也没什么新的东西了,就是继续添加特征调参优化,最终整理成文档就成了任务二,不过代码要重新整理一下。
还是参考之前第一名的特征列表继续添加:
获取日期特征
- 领取优惠券是星期几
- 领券日是否为休息日
- 领取优惠券是一月的第几天
获取基本特征
- 用户领券数
- 用户领取特定优惠券数
- 用户此次之前 / 后领取的所有优惠券数目
- 用户此次之前 / 后领取的特定优惠券数目
- 用户上/下一次领取的时间间隔
- 用户上/下一次领取特定优惠卷的时间间隔
- 用户领取特定商家的优惠券数目
- 用户领取的不同商家数目
- 用户当天领券数
- 用户当天领取特定优惠券数
- 用户领取的所有优惠券种类数目
- 用户是否在同一天重复领取了特定优惠券
- 商家被领取的优惠券数目
- 商家被领取的特定优惠券数目
- 商家被多少不同用户领取的数目
- 商家发行的所有优惠券种类数目
历史区间的商家相关的特征
- 历史上商家优惠券被领取次数
- 历史上商家优惠券被领取后不核销次数
- 历史上商家优惠券被领取后核销次数
- 历史上用户对该优惠券的核销率
- 历史上商家优惠券核销的平均消费折率
- 历史上商家优惠券核销的最小消费折率
- 历史上商家优惠券核销的最大消费折率
- 历史上商家提供的不同优惠卷数目
- 历史上领取商家优惠券的不同用户数量
- 历史上核销商家优惠券的不同用户数量
- 历史上核销商家优惠券的不同用户数量占领取不同的用户比重
- 历史上商家优惠券平均每个用户核销多少张
- 历史上商家被核销过的不同优惠券数量
- 历史上商家平均每种优惠券核销多少张
- 历史上商家被核销过的不同优惠券数量占所有领取过的不同优惠券数量的比重
- 历史上商家被核销优惠券中的平均用户 - 商家距离
- 历史上商家被核销优惠券中的最小用户 - 商家距离
- 历史上商家被核销优惠券中的最大用户 - 商家距离
历史区间的优惠券相关的特征
- 历史上该优惠卷被领取次数
- 历史上该优惠卷被消费次数
- 历史上该优惠卷未被消费次数
- 历史上该优惠卷被消费率
- 历史上该优惠卷15天内核销时间率
- 历史上该优惠卷15天内被核销的平均时间间隔
- 历史上满减优惠券最低消费的中位数
历史区间的用户相关的特征
- 历史上用户领取优惠券次数
- 历史上用户获得优惠券但没有消费的次数
- 历史上用户获得优惠券并核销次数
- 历史上用户领取优惠券后进行核销率
- 历史上用户核销优惠券的平均消费折率
- 历史上用户核销优惠券的最低消费折率
- 历史上用户核销优惠券的最高消费折率
- 历史上用户领取多少个不同的商家
- 历史上用户核销过优惠券的不同商家数量
- 历史上用户领取不同的商家数量占所有不同商家的比重
- 历史上用户核销过优惠券的不同商家数量占所有不同商家的比重
- 历史上用户核销过优惠券的不同商家数量占领取过的不同商家的数量的比重
- 历史上用户领取多少个不同的优惠卷
- 历史上用户领取的不同的优惠卷数量占所有不同优惠卷的比重
- 历史上用户对领卷商家的15天内的核销数
- 历史上用户平均核销每个商家多少张优惠券
- 历史上用户核销优惠券中的平均用户 - 商家距离
- 历史上用户核销优惠券中的最大用户 - 商家距离
- 历史上用户核销优惠券中的最小用户 - 商家距离
历史区间的商家-优惠券相关的特征
- 历史上商家被领取的特定优惠券数目
历史区间的用户-优惠券相关的特征
- 历史上用户领取特定优券次惠数
- 历史上用户消费特定优券次惠数
- 历史上用户对特定优惠券的核销率
历史区间的用户-商家相关的特征
- 历史上用户领取商家的优惠券次数
- 历史上用户领取商家的优惠券后不核销次数
- 历史上用户领取商家的优惠券后核销次数
- 历史上用户领取商家的优惠券后核销率
用户-商家-优惠卷综合特征
- 历史上用户对每个商家的不核销次数占用户总的不核销次数的比重
- 历史上用户对每个商家的优惠券核销次数占用户总的核销次数的比重
- 历史上用户对每个商家的不核销次数占商家总的不核销次数的比重
- 历史上用户对每个商家的优惠券核销次数占商家总的核销次数的比重
- 历史上商家被核销过的不同优惠券数量占所有领取过的不同优惠券数量的比重
一共提取了81个特征,在前77个特征加入后,线上提交得分还是只有0.73左右,但是加入最后四个特征:
- 用户上/下一次领取的时间间隔
- 用户上/下一次领取特定优惠卷的时间间隔
之后,提交得分一下冲到了0.7729,进入排行榜第450名!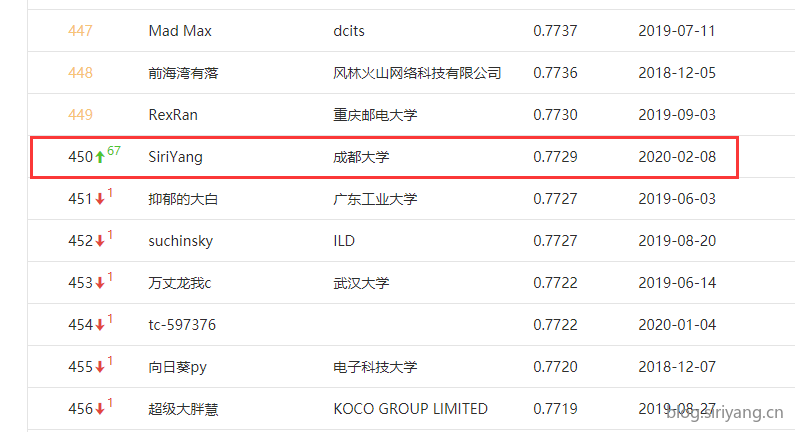
确实如github教程所说这几个特征有点bug,只要加入必然会有大的提升。想来也是,当你再次领取同一个优惠卷的时候,多半上一张已经用掉了。
再次进行参数调优:
1 | [mean: 0.86952, std: 0.00536, params: {'max_depth': 3, 'min_child_weight': 1}, |
不过训练提交以后得分只有0.7723。
结语
总的来说80多个特征已经够多了,多的我都取不出名字来了。接下来的工作就是继续调参,并对数据过拟合训练后查看筛选出重要性最高的特征,过多的冗余特征会使学习训练变慢。还有就是尝试一下其他训练模型算法,进行模型融合。

