前言
最近准备看一下计算机操作系统的书。现在习惯GoodNote上看PDF,并用MarkDown做笔记发布到博客上做知识管理。但大多数PDF都是扫描的图片,没法直接复制文本,以前都是累死累活的靠自己手打,今天突然想到为啥不自己写个脚本OCR一下呢…我人傻了。o(TヘTo)
正文
其实要做一个OCR脚本很简单,调接口就完事了,好在百度云的API每天都有免费使用量,腾讯云只能免费体验一段时间。
注册账号
开局一个号,API全靠嫖,你要是没有账号我也没法子了,动动手指而已,注册也没多麻烦。我想现在大多数人应该都是有百度账号的吧,毕竟还要用百度云盘。
获取API密匙
登陆百度云,不是云盘那个云,是云计算的云。然后在产品目录搜索“文字识别”。
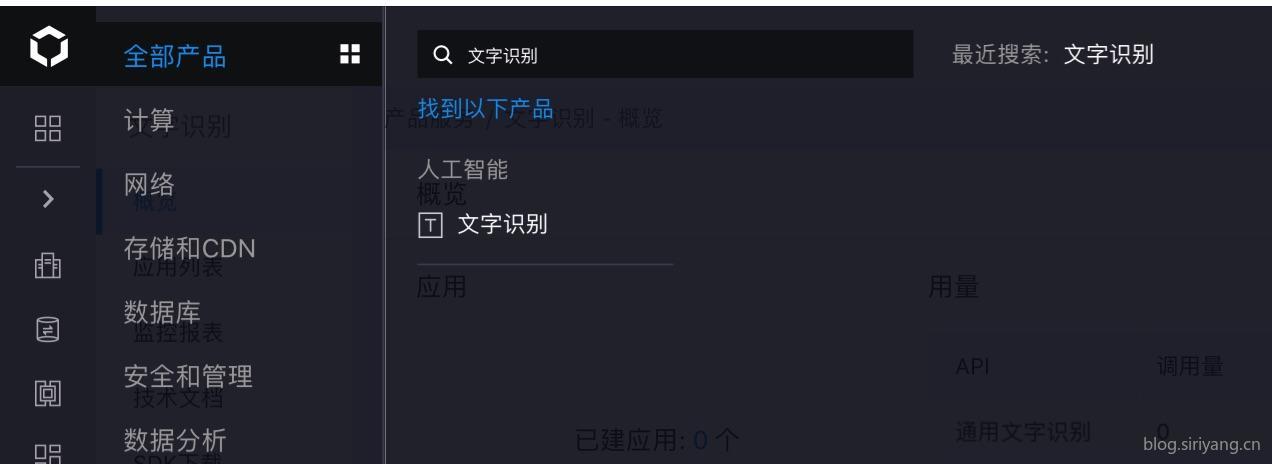
然后在这个界面下方可以看到你免费版每天的使用次数,可以识别的种类特别多,我准备选用的是不带坐标信息的通用文字识别高精度版,每天可以白嫖500次,我一个人用的话完全足够了。要真是不够用,用完了大不了切换到普通版本将就着用,正常使用50000次每天不可能不够用,除非你写个for循环使劲糟蹋…
后面那一栏的QPS限制是你的并发计算量,也就是说你的免费版本只能并发执行两个识别运算,一个人或少数人使用倒是问题不大。
然后点击创建应用。
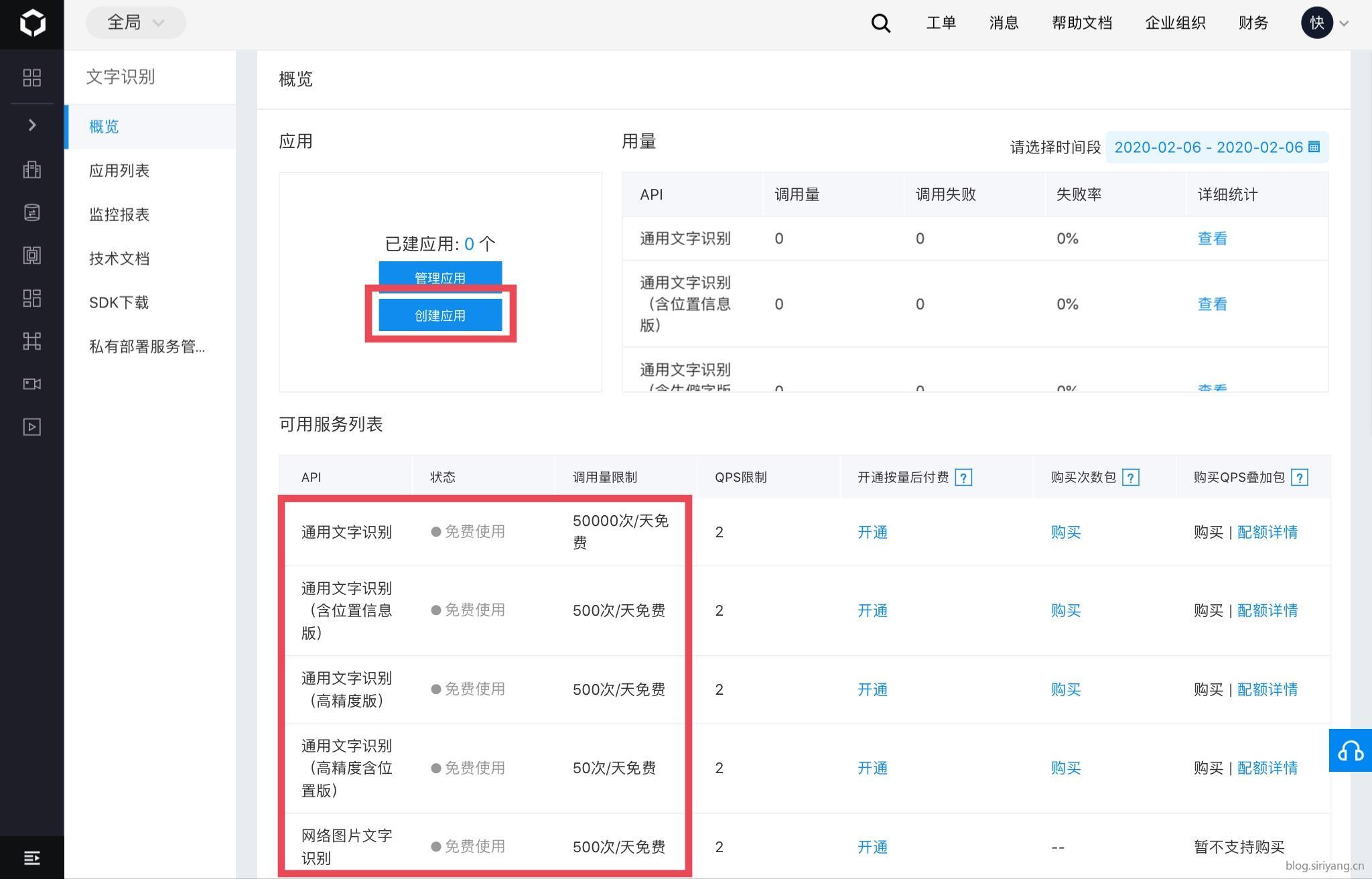
应用配置这里把名字和备注填好就行了,其他没啥好改的,所有类型的文本识别接口都默认打开了。

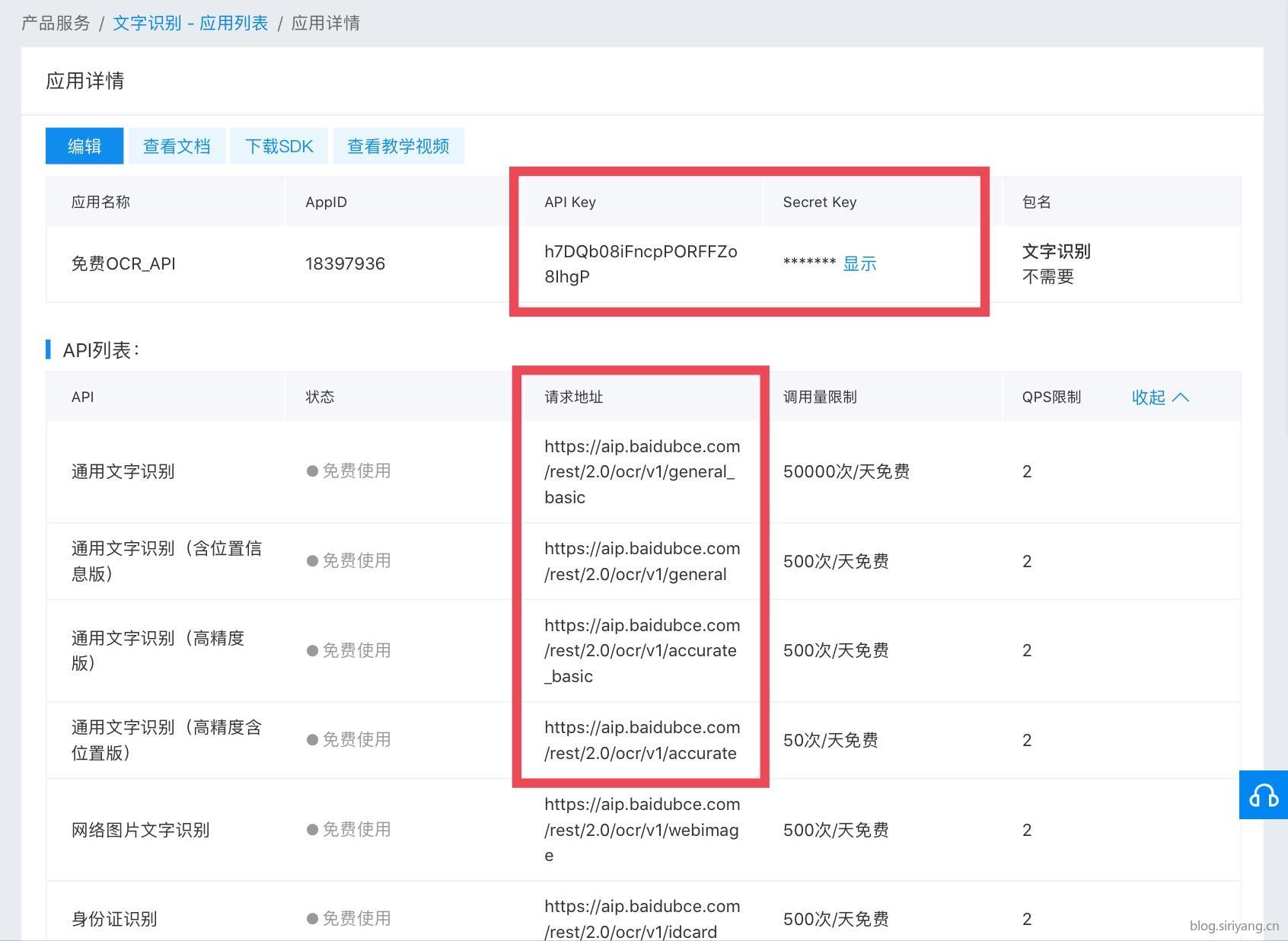
创建好以后进入应用详情页面。上方红框里的内容是待会儿会用到的API访问密钥,这个一定要保存好,不要被别人知道了,尤其是像python这种脚本代码在分享传播之前最好把密钥删掉。调用接口除了使用密钥以外还可以使用一些其他类似证书授权的方法,我这里就不在多做解释了。
下方红框的URL决定了之后你要使用哪个版本的API。
点击左上方的查看文档也有API各种语言的示例教程和更多使用方法,以后开发其他的项目时可以来这里学习。
配置代码
首先拷贝下方的代码到自己的pythonista中,然后在分享扩展面板将其导入,之后这里将作为程序启动的入口。
在使用之前首先要配置一点信息,就是我们上面注册账号获得的API密钥,并在下面填上你要选择使用的相应版本的接口链接,我默认已经为你填上了通用文本高精度版本了。
1 | # API_key 为官网获取的AK, Secret_Key 为官网获取的SK |
使用方法
你需要选择一张图片,并将它分享到分享面板或者复制到粘贴板再打开分享面板都可以,代码会先查找是否有分享的图片,没有的话再检查粘贴板里有没有图片。比如说我这里是GoodNote中框选的一张截图。

然后选择运行Pythonista代码,并启动之前导入的代码。
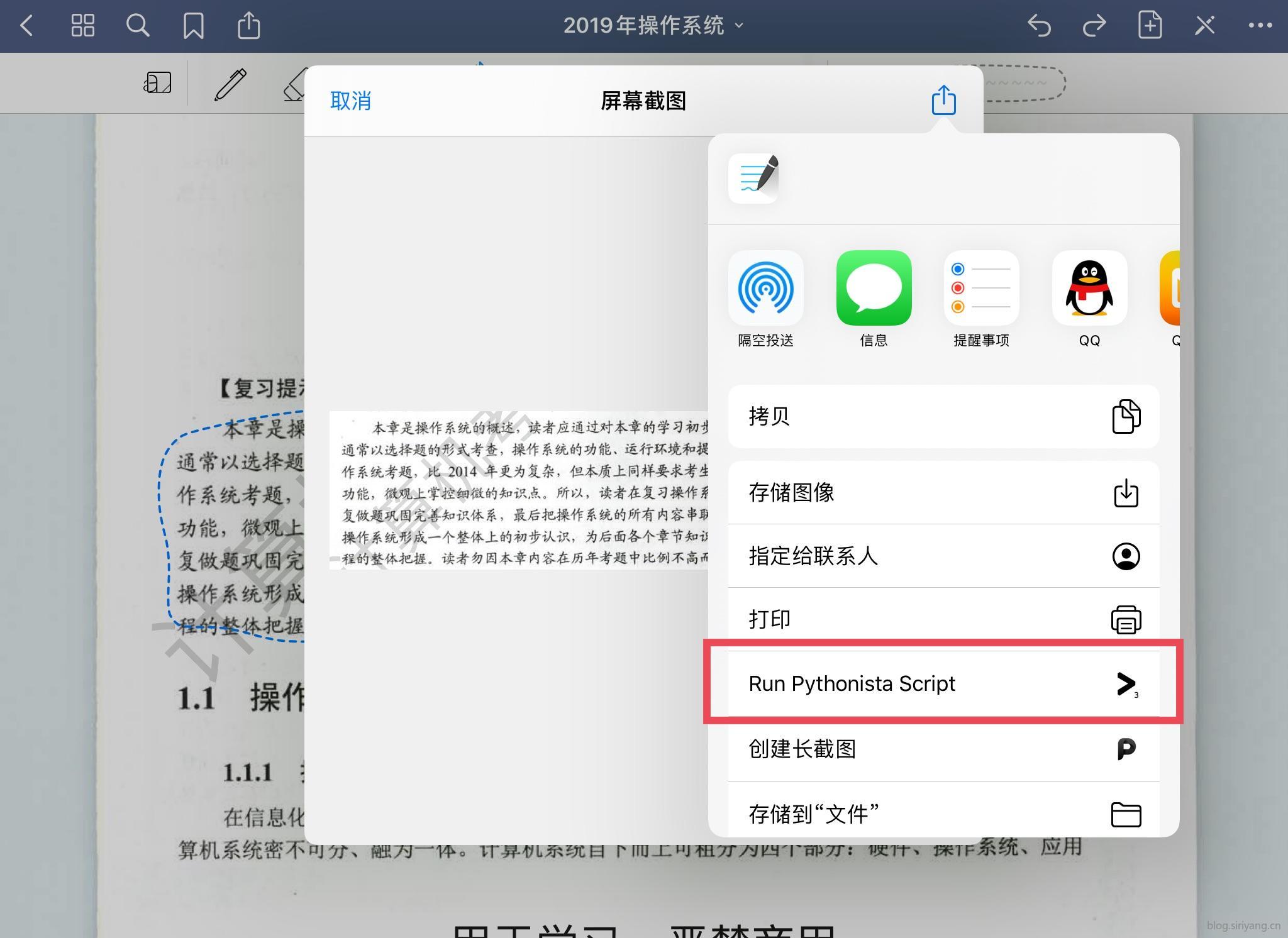
整个窗口有两个页面,一个是你选择识别的图片,还有一个是识别的结果。
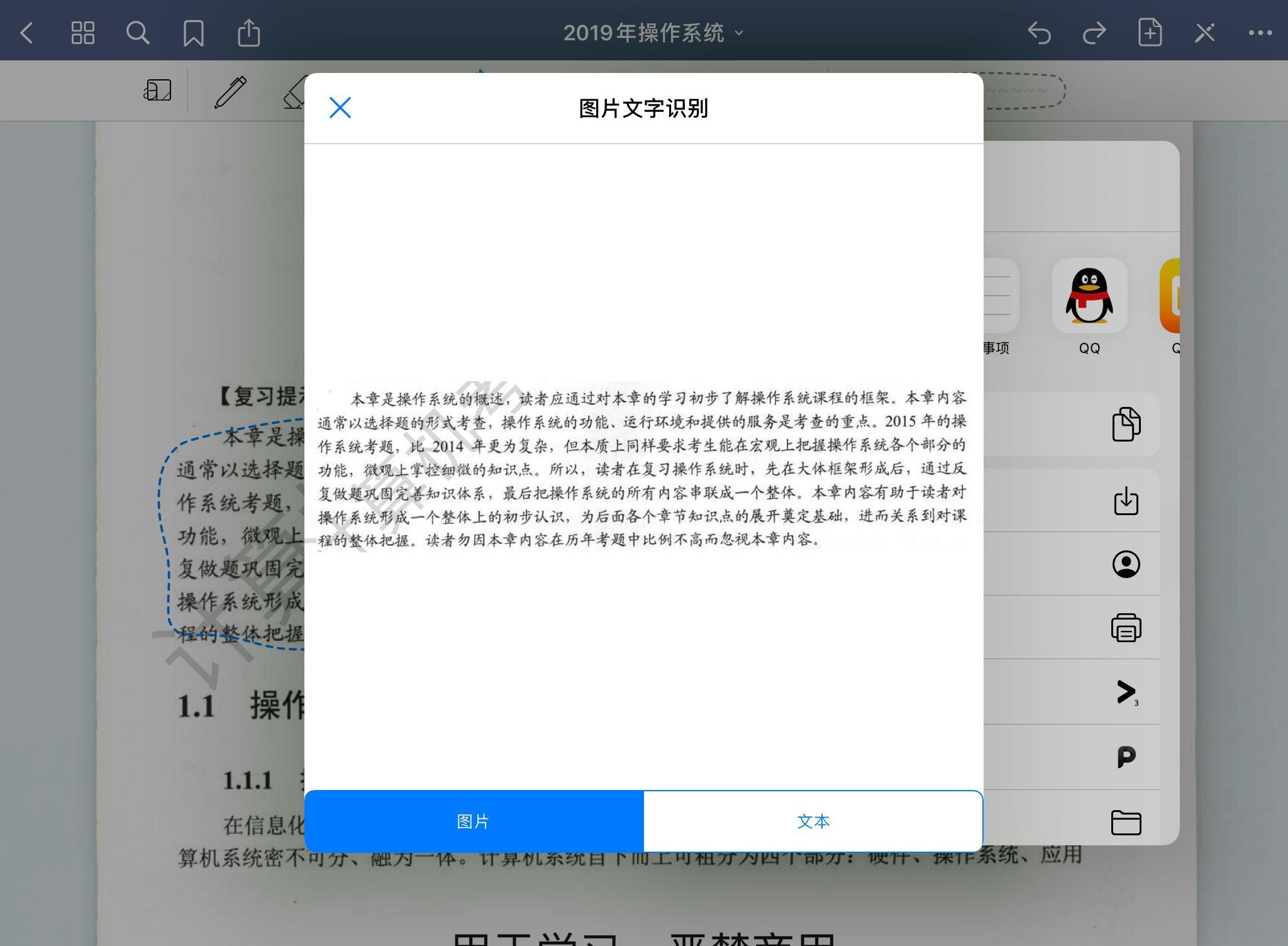
程序会自动将识别结果复制到你的粘贴板,顶行将会显示一些提示信息。API传回的识别结果是一行一句的,所以有多个段落的话我也不知道哪些是一段的,所以干脆就全部拼接起来,由用户自己分段。我个人用的习惯是一次识别一段话,顶多也就两三段,打两个回车就好了。
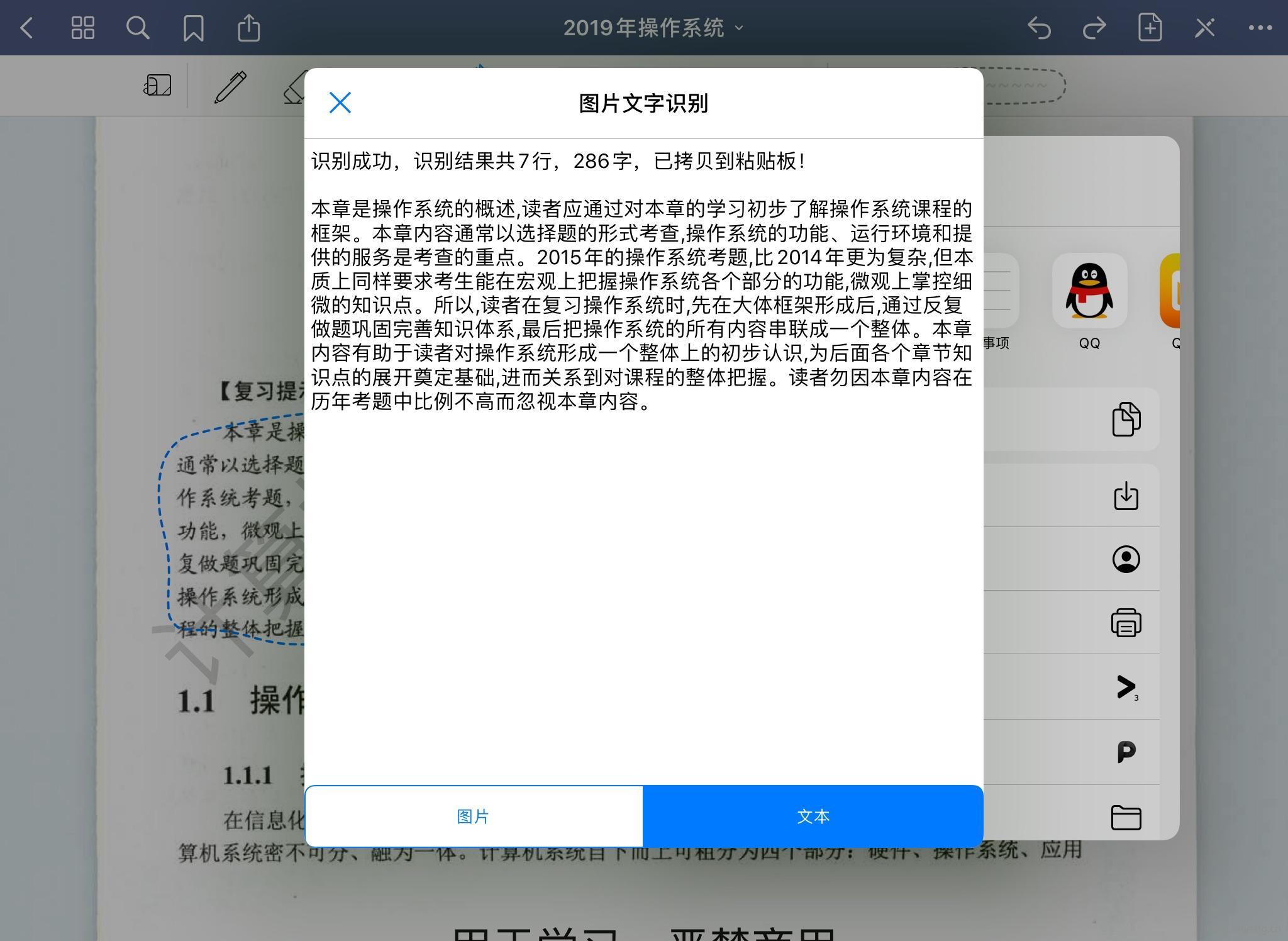
这是没有拼接的样子,虽然在有多段和小标题的情况下可以明显的将其区分出来,但是后面大整段都被分成一行一行的并不方便使用。

代码
1 | # -*- coding:utf-8 -*- |

