前言
在之前写的基于Pythonista和百度API的高精度文本识别脚本的基础上添加英文翻译功能,以方便在iPad上看一些英文文章和论文,省去了切换app的麻烦。
正文
在基于Pythonista和百度API的高精度文本识别脚本的基础上只需要稍加修改,在图片OCR成文本以后再调用翻译API接口就行了。脚本使用方法和之前相同,可参考上一篇文章的配置教程。这里主要介绍翻译API的获取方法和源码。
获取百度翻译API
使用百度账号登录百度翻译API的首页,注册成为开发者:
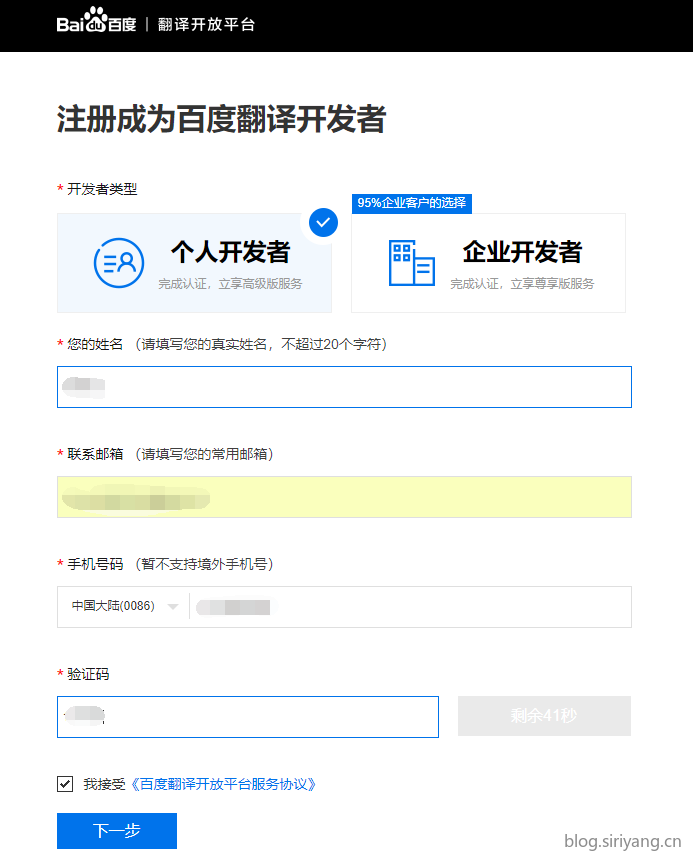
个人使用的话这里选择标准版就够了,高级版的话需要进行一个身份认证。

然后选择开通你要是用的服务,通用翻译API就够用了,虽然下面有拍照翻译SDK可以直接将图片翻译成目标语言,但是默认是安卓SDK的形式,想要改成web通用API的话需要提交申请。
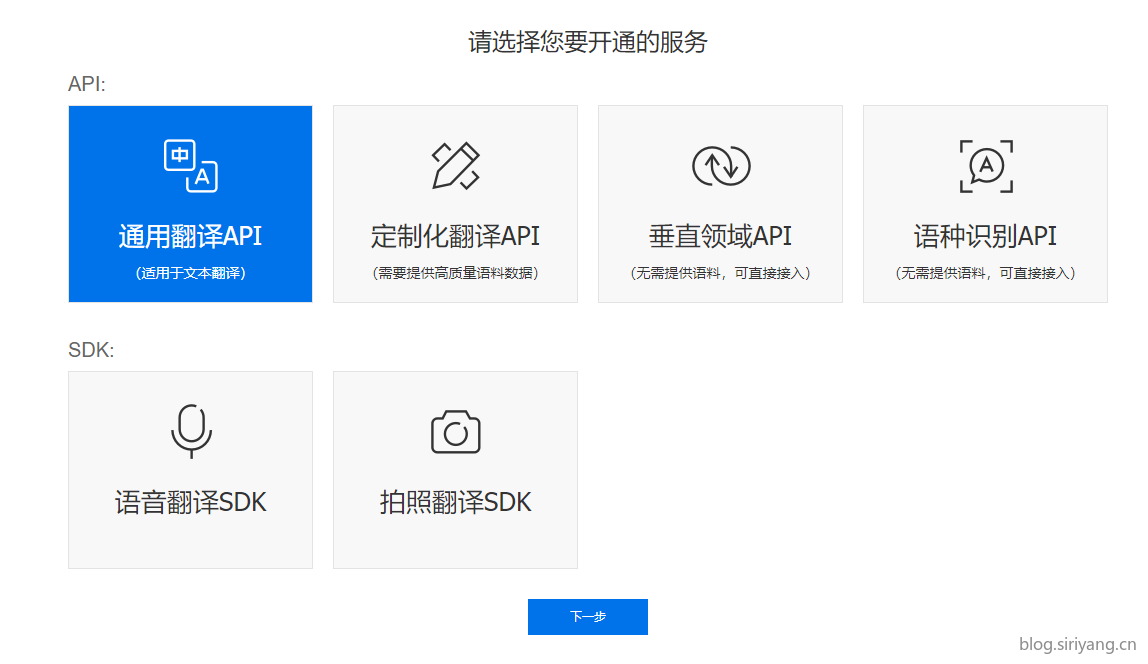
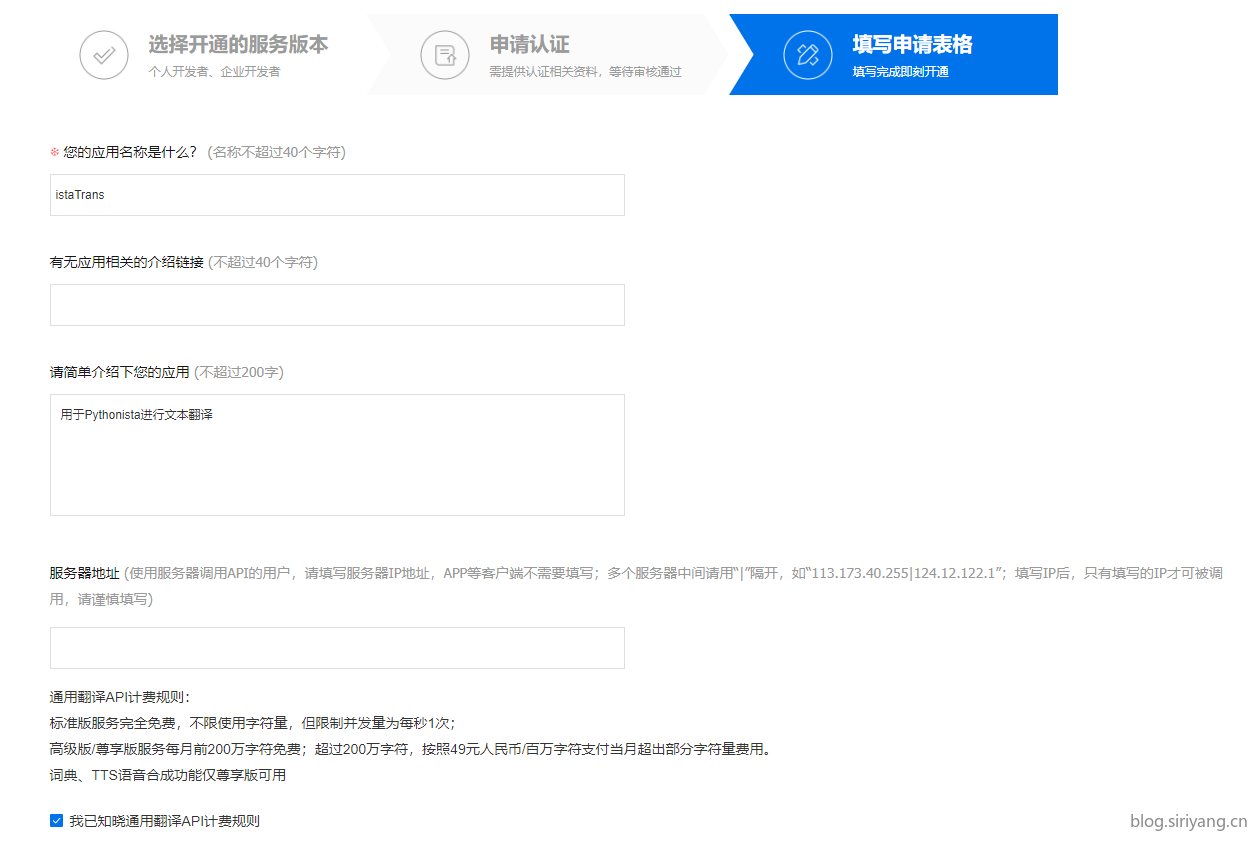
最后为你的应用取一个名字就完成注册了。
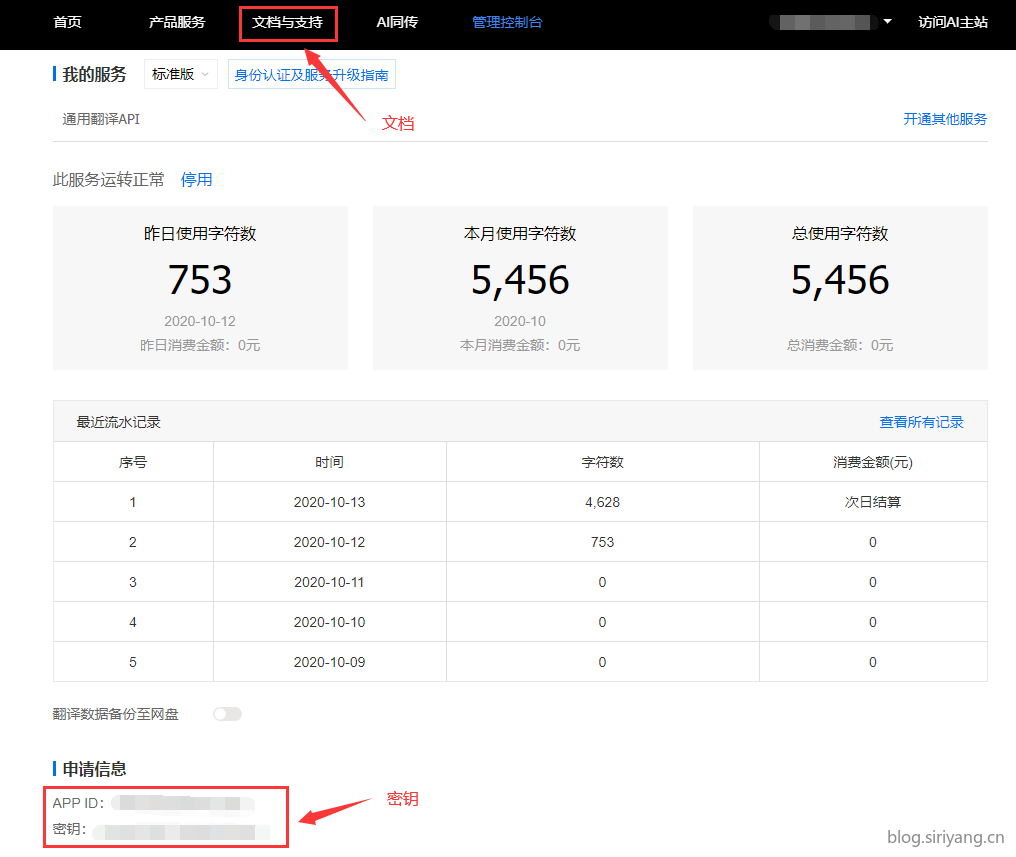
登录以后进入控制台页面就可以查看当前的数据用量,不过标准版完全免费敞开了用,高级版每月200万字符的免费额度基本上够用了。在上方可以查看API的使用文档,下载各种语言的示例代码,下方可以直接查看API的访问密钥。
1 | #百度通用翻译API,不包含词典、tts语音合成等资源,如有相关需求请联系translate_api@baidu.com |
在尝试了好几家的API接口以后最后选择的百度API,文档相对完善,注册操作简单。如果想要获得更好的使用体验也可以尝试去获取有道、谷歌等翻译API。就目前的使用情况来说百度的翻译效果还算可以了。
效果展示
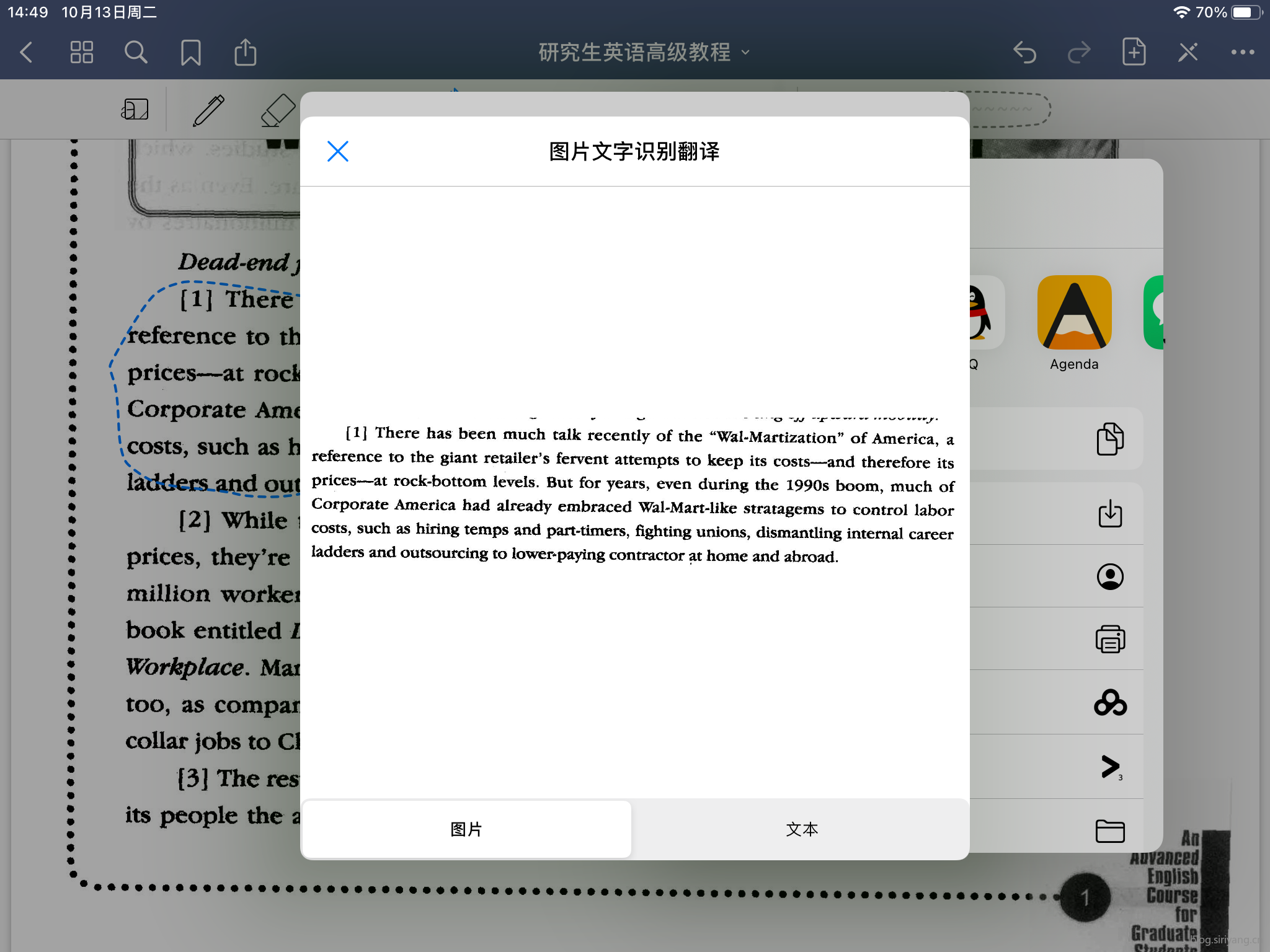
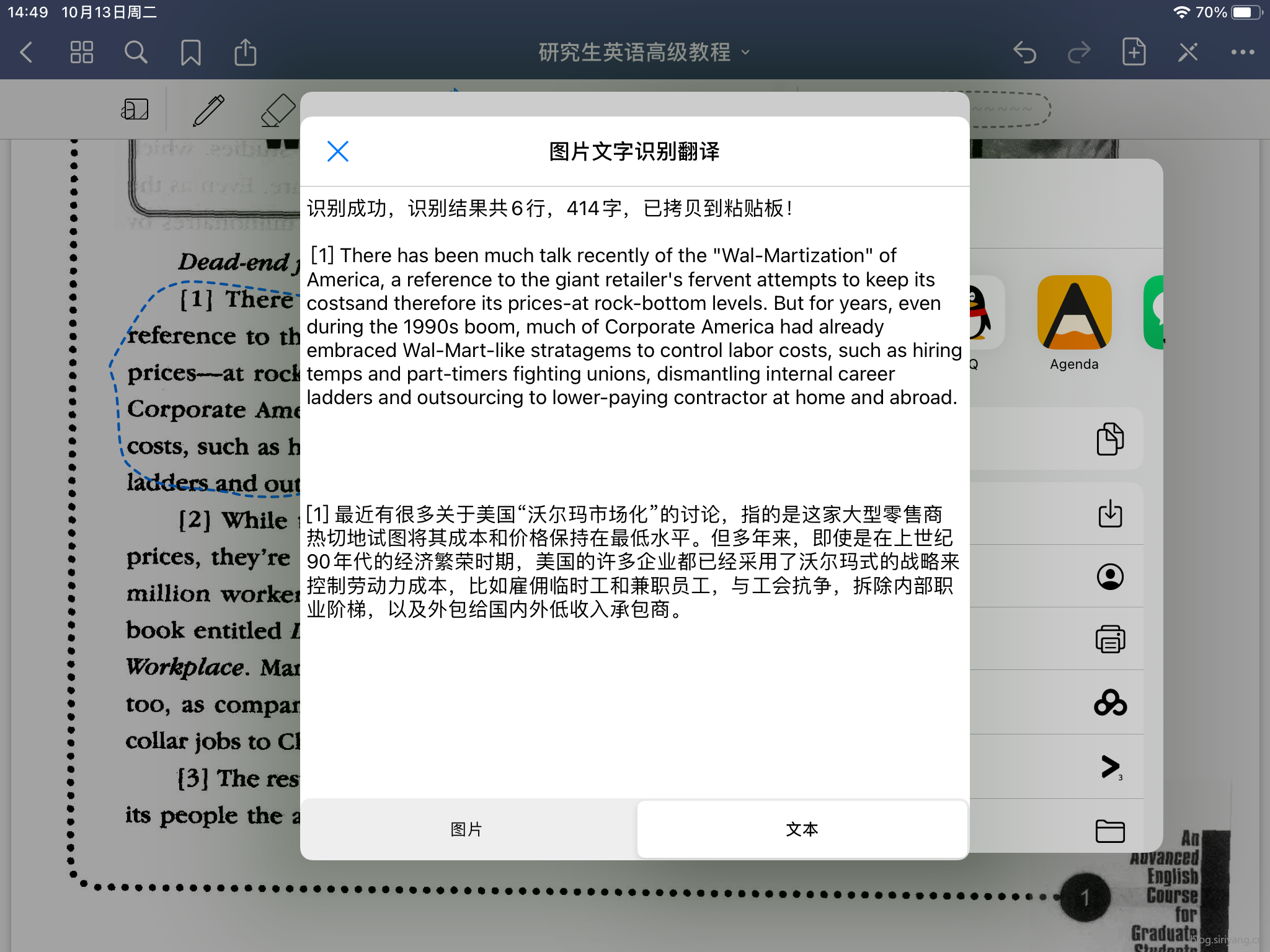
代码
1 | # -*- coding:utf-8 -*- |

