阅读理解概述
所谓的机器阅读理解(Machine Reading Comprehension, MRC)就是给定一篇文章,以及基于文章的一个问题,让机器在阅读文章后对问题进行作答。
常见任务定义
MRC 的常见任务主要有六个:完形填空、多项选择、片段抽取、生成式、会话和多跳推理:
- 完形填空:将文章中的某些单词隐去,让模型根据上下文判断被隐去的单词最可能是哪个。
- 多项选择:给定一篇文章和一个问题,让模型从多个备选答案中选择一个最有可能是正确答案的选项。
- 片段抽取:给定一篇文章和一个问题,让模型从文章中抽取连续的单词序列,并使得该序列尽可能的作为该问题的答案。
- 生成式:给定一篇文章和一个问题,让模型生成一个单词序列,并使得该序列尽可能的作为该问题的答案。与片段抽取任务不同的是,该序列不再限制于是文章中的句子。
- 会话:目标与机器进行交互式问答,因此,答案可以是文本自由形式(free-text form),即可以是跨距形式,可以是“不可回答”形式,也可以是“是/否”形式等等。
- 多跳推理:问题的答案无法从单一段落或文档中直接获取,而是需要结合多个段落进行链式推理才能得到答案。因此,机器的目标是在充分理解问题的基础上从若干文档或段落中进行多步推理,最终返回正确答案。
评价指标
- 对于完形填空和多项选择类型的任务,由于答案都是来源于已经给定的选项集合,因此使用 Accuracy 这一指标最能直接反映模型的性能。
- 对于抽取式和多跳推理类型的任务,使用 Exact Match(EM) 和 F1 值。EM 是指数据集中模型预测的答案与标准答案相同的百分比,F1 值是指数据集中模型预测的答案和标准答案之间的平均单词的覆盖率。多跳推理数据集,还提出了针对支持证据(supporting fact)的 EM 和 F1 值。
- 对于会话类型的任务,由于其答案是文本自由形式,因此并没有一种通用的评价指标,该类任务的评价指标主要由数据集本身决定。
- 对于生成式类型的任务,由于答案是人工编辑生成的,而机器的目标是使生成的答案最大限度地拟合人工生成的答案,因此该类任务一般使用机器翻译任务中常用的 BLEU-4 和 Rouge-L 两种指标。Rouge(recall-oriented understudy for gisting evaluation)同时也是自动文本摘要任务的重要评测指标。
阅读理解架构
基于端到端神经网络的机器阅读理解模型大都采用如下图所示的嵌入层、编码层、交互层、输出层的 4 层架构:
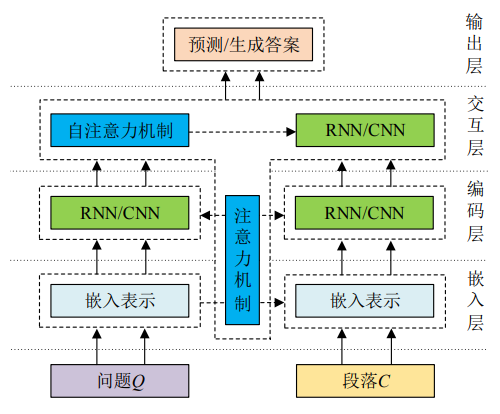
嵌入层
基于神经网络的机器阅读理解模型的第 1 个关键步骤就是将单词表示成高维、稠密的实值向量。One-Hot 词向量表示方法最大的问题在于这种稀疏向量无法体现任何单词之间的语义相似度信息。高维映射的词嵌入方法可以有效解决上述方法带来的问题,语义相似的单词可以在几何空间中被编码成距离相近的向量。将嵌入级别细粒度化至字符级别、将静态单词向量变成上下文相关的动态向量或将单词本身的特征一起嵌入到词向量中,都会在一定程度上提高模型的性能。
字符嵌入
字符嵌入用来获取一个单词在字符级别的向量表示,采用 char-level 的词向量能够在一定程度上缓解文本中出现未登录词(out-of-vocabulary,简称 OOV)的问题。
词嵌入
词向量能够基于单词的分布式假设,从大规模无标签的文本语料库中学习获得。在机器阅读理解任务中,使用最多的是 Word2Vec、GloVe 以及 Fasttext 这 3 种单词级别的嵌入模型。
- Word2Vec 词向量:该模型具体可以分为连续词袋模型(continuous bag-of-word,简称 CBoW)以及跳跃元语法模型(skip-gram)两种:前者是从上下文对目标单词的预测中学习词向量;后者则相反,是从目标单词对其上下文的预测中学习词向量。
- GloVe 词向量:GloVe 学习的是词向量的共现概率比值,而不是词本身的出现概率。
- Fasttext 词向量:Fasttext 词向量本质上是 Fasttext 快速文本分类算法的副产物,该模型的提出,旨在解决 Word2Vec 和GloVe 模型忽略单词内部结构,从而导致词的形态学特征缺失的问题。
上下文嵌入
将词的表征扩展到上下文级别,将每个单词表示为整个输入句子的函数映射,即根据当前的句子来体现一个词在特定上下文的语境里面该词的语义表示,使其动态地蕴含句子中上下文单词的特征,从而提高模型的性能。目前较为流行的用于上下文级别嵌入的模型有 CoVe、ELMo 以及 BERT等预训练模型。
- CoVe 上下文向量:一个单词除了和与之有着语义相似性的单词在向量空间中距离较近以外,还和出现这个单词的句子中的上下文单词也有着一定的关联。一个句子中的每一个单词应该共享其上下文中其他单词的表征能力,这样可以进一步提升模型性能。实验表明:将上下文向量与词向量拼接得到新的词嵌入表征,即 $\tilde{w}=[GloVe(w);CoVe(w)]$ 作为模型的输入,能进一步提高模型性能。
- ELMo 上下文向量:一个好的词嵌入应该包括两个部分:一是包含诸如语法和语义等复杂特征;二是能够识别这个单词在不同上下文中的不同使用意义,即一词多义的区分;此外词表征应该结合模型的所有内部状态。实验表明:高层次的 LSTM 倾向于捕捉上下文相关的信息,而低层次的 LSTM 倾向于捕捉语法相关的信息。ELMo 采用了耦合双向 LSTM 语言模型(biLM)来生成预训练的上下文词向量。
- BERT 上下文向量:ELMo 存在的两个潜在问题:一是 biLM 模型并不是完全双向的,即句子从左到右和从右到左的 LSTM 过程并不是同时进行的;二是传统语言模型的数学原理决定了它的单向性,对于完全双向的 Bi-LSTM 来说,只要层数增加,就会存在预测单词“自己看见自己”的问题。BERT 预训练模型通过建立双向 Transformer 架构,加以采用遮蔽语言模型以及连续句子预测来解决上述问题该模型进一步增强了词向量模型的泛化能力,充分描述了字符级别、单词级别和句子级别的关系特征。
特征嵌入
特征嵌入本质上就是将单词在句子中的一些固有特征表示成低维度的向量,包括单词的位置特征(position)、词性特征(POS)、命名实体识别特征(NER)、完全匹配特征(em)以及标准化术语频率(NTF)等等,一般会通过拼接的方式将其与字符嵌入、词嵌入、上下文嵌入一起作为最后的词表征。
编码层
编码层的目的是将已经表示为词向量的 Tokens(词的唯一标记单位)通过一些复合函数进一步学习其内在的特征与关联信息。提取特征的本质就是在对样本进行编码。
循环神经网络(RNN/LSTM/GRU)
循环神经网络是神经网络的一种,主要用来处理可变长度的序列数据。不同于前馈神经网络,RNNs 可以利用其内部的记忆来处理任意时序的输入序列,这使得它更容易处理机器阅读理解数据集中的问题和段落序列。
为了优化传统 RNN 模型的性能(例如解决 RNN 出现的梯度消失问题),研究者们提出了许多 RNN 的变体,其中比较著名且常用的变体有长短期记忆网络(long short-term memory,简称 LSTM)和门控循环单元(gatedrecurrent unit,简称 GRU)。在 MRC 甚至整个 NLP 领域的应用中,LSTM 是最具有竞争性且使用最为广泛的 RNN 变体,研究者们常用双 LSTM(BiLSTM)模型对问题 Q 和段落 C 进行编码。
卷积神经网络(CNN)
使用 RNN 模型对问题 Q 和段落 C 进行编码时,会导致模型训练和推理的速度变得非常缓慢,这使得模型无法应用于更大的数据集,同时无法应用于实时系统中。利用 CNN 模型善于提取文本局部特征的优点,同时采用自注意力机制来弥补 CNN 模型无法对句子中单词的全局交互信息进行捕捉的劣势。实验结果表明:在不失准确率的情况下,Yu 等人提出的模型在训练时间上较先前的模型快了 3~13 倍。但总体而言,CNN 模型在 MRC 任务中仍使用较少。
交互层
交互层是整个神经阅读理解模型的核心部分,它的主要作用是负责段落与问题之间的逐字交互,从而获取段落(问题)中的单词针对于问题(段落)中的单词的加权状态,进一步融合已经被编码的段落与问题序列。
注意力机制
当段落和问题序列通过注意力机制后,神经阅读理解模型就能学习到两者之间单词级别的权重状态,这大大提高了最后答案预测或生成的准确率。
自注意力机制
将一个序列自己与自己进行注意力学习,进而学习句子内部的词依赖关系,捕获句子的内部结构,以此来替代 RNN 模型对序列进行编码。
注意力机制的另一个优点是大大增强了模型的可解释性,能够让研究者们清楚地看到单词之间的关联程度。
输出层
输出层主要用来实现答案的预测与生成,根据具体任务来定义需要预测的参数。
针对抽取式任务,神经阅读理解模型需要从某一段落中找到一个子片段(span or sub-phrase)来回答对应问题,这一片段将会以在段落中的首尾索引的形式表示,因此,模型需要通过获取起始和结束位置的概率分布来找到对应的索引。
针对完形填空任务,神经阅读理解模型需要从若干个答案选项中选择一项填入问句的空缺部分,因此,模型首先需要计算出段落针对问题的注意力值,然后通过获取选项集合中候选答案的概率预测出正确答案
针对多项选择任务,神经阅读理解模型需要从 k 个选项中选出正确答案,因此,模型可以先通过 BiLSTM将每一个答案进行编码得到 ai,之后与 u 进行相似度对比,预测出正确的答案。
针对生成式任务,由于答案的形式是自由的(free-form),可能在段落中能找到,也可能无法直接找到而需要模型生成,因此,模型的输出不是固定形式的,有可能依赖预测起止位置的概率(与抽取式相同),也有可能需要模型产生自由形式的答案。
针对会话类和多跳推理任务,由于只是推理过程与抽取式不同,其输出形式基本上与抽取式任务相同,有些数据集还会预测“是/否”、不可回答以及“能否成为支持证据”的概率。
针对开放域的阅读理解,由于模型首先需要根据给定问题,从例如 Wikipedia 上检索多个相关文档(包含多个段落),再从中阅读并给出答案。
数据集
| 名称 | 类别 | 语言 | #问题 | #段落 | 问题来源 | 段落来源 | 不可回答 | 是/否类 |
|---|---|---|---|---|---|---|---|---|
| CNN/DailyMail | 完形填空 | 英文 | 1.38M | 312K | 生成 | 新闻 | - | - |
| CBT | 完形填空 | 英文 | 688K | 108 | 生成 | 少儿图书 | - | - |
| CLOTH | 完形填空 | 英文 | 99K | 7.1K | 英语考试 | 英语考试 | - | - |
| PeopleDaily/CFT | 完形填空 | 中文 | 100K | 28K | 生成 | 新闻/童话 | - | - |
| TQA | 多项选择 | 英文 | 26.3K | 1 | 076 | 理科课程 | 理科课程 | - |
| SciQ | 多项选择 | 英文 | 13.7K | N/A | 众包 | 科学考试 | - | - |
| MCScript | 多项选择 | 英文 | 14K | 2 | 100 | 众包 | 日常语料 | - |
| RACE | 多项选择 | 英文 | 100K | 28K | 英语考试 | 英语考试 | - | - |
| ARC | 多项选择 | 英文 | 7 | 787 | N/A | 科学考试 | 科学考试 | √ |
| WikiQA | 抽取式 | 英文 | 3 | 047 | N/A | 必应日志 | 维基百科 | - |
| SQuAD1.1 | 抽取式 | 英文 | 108K | 536 | 众包 | 维基百科 | - | - |
| NewsQA | 抽取式 | 英文 | 120K | 12.7K | 众包 | 新闻 | √ | - |
| SearchQA | 抽取式 | 英文 | 140K | 6.9M | 网页 | 网页 | - | - |
| TriviaQA | 抽取式 | 英文 | 95.9K | 663K | 网页 | 维基/网页 | - | - |
| SQuAD2.0 | 抽取式 | 英文 | 151K | 505 | 众包 | 维基百科 | √ | - |
| SQA | 多轮对话 | 英文 | 17.6K | 6 | 066 | 众包 | 维基百科 | - |
| CSQA | 多轮对话 | 英文 | 1.6M | 200K | 众包/生成 | 知识图谱 | √ | √ |
| CQA | 多轮对话 | 英文 | 34.7K | N/A | 众包/生成 | Web | 知识库 | - |
| CoQA | 多轮对话 | 英文 | 127K | 8K | 众包 | 多领域 | √ | √ |
| QuAC | 多轮对话 | 英文 | 98.4K | 13.6K | 众包 | 维基百科 | √ | √ |
| DuReader | 生成式 | 中文 | 200K | 1M | 百度日志 | 网页 | √ | √ |
| MS MARCO | 生成式 | 英文 | 100K | 200K | 必应日志 | 网页 | √ | √ |
| NarrativeQA | 生成式 | 英文 | 46K | 1.5K | 众包 | 书籍/电影 | - | - |
| HotpotQA | 多跳推理 | 英文 | 112K | N/A | 众包 | 维基百科 | - | √ |
神经网络模型
| 模型 | 创新点 | 性能 | 模型 | 创新点 | 性能 |
|---|---|---|---|---|---|
| BiDAF | 双向注意力机制 | 77.3 F1 (SQuAD1.1) | U-Net | 通用节点记录信息 | 72.6 F1 (SQuAD2.0) |
| DCN | HMN 模块 | 82.8 F1 (SQuAD1.1) | BERT | 预训练模型 | 91.8 F1 (SQuAD1.1) |
| DrQA | Wikipedia 知识源 | 79.0 F1 (SQuAD1.1) | ElimiNet | 引入排除法 | 44.5 Acc (RACE) |
| DrQA | Wikipedia 知识源 | 25.4 EM (TREC) | CSA | 空间卷积-池化 | 50.9 Acc (RACE) |
| DrQA | Wikipedia 知识源 | 36.5 EM (WikiMov.) | MRU | MRU 单元 | 50.4 Acc (RACE) |
| FastQA | 轻量级模型 | 77.1 F1 (SQuAD1.1) | MRU | MRU 单元 | 19.8 Bleu-4 (Narra.) |
| R-Net | 自注意力机制 | 88.2 F1 (SQuAD1.1) | RMR+ | 重注意力、知识净化 | 27.5 Bleu-4 (Narra.) |
| QANet | CNN+自注意力 | 87.8 F1 (SQuAD1.1) | FlowQA | 引入对话流 | 75.0 F1 (CoQA) |
| SLQA | 分层注意力融合 | 82.8 F1 (SQuAD1.1) | GraphFlow | 引入图神经网络 | 77.3 F1(CoQA) |
| Read+Ver | 独立辅助损失函数 | 74.3 F1 (SQuAD2.0) | DFGN | 动态融合实体图 | 59.82 F1 (HotpotQA) |
| KAR | 引入知识库辅助 | 83.5 F1 (SQuAD1.1) | QFE | 聚焦提取支持证据 | 59.61 F1 (HotpotQA) |
未来研究方向
当前面临的问题
- 模型缺乏深层次的推理能力
- 模型的鲁棒性与泛化能力太差
- 对于模型来说,是表征重要还是架构重要
- 模型的可解释性太差
未来研究方向
- 构建更贴近人类自然语言习惯的数据集
- 构建兼具速度与性能的模型
- 在训练中融入对抗实例,以提高模型的鲁棒性与泛化能力
- 提高模型的可解释性
参考资料
- 顾迎捷,桂小林,等.基于神经网络的机器阅读理解综述[J].软件学报,2020,31(7):2095-2126.
- 李舟军,王昌宝.基于深度学习的机器阅读理解综述[J].计算机科学,2019,46(7):7-12.
- 张超然,裘杭萍,孙毅,等.基于预训练模型的机器阅读理解研究综述[J].计算机工程与应用,2020,56(11):17-25.
- NLP 作业:机器阅读理解(MRC)综述
- 机器阅读理解综述Neural Machine Reading Comprehension Methods and Trends(略读笔记)

