摘要:远程监督关系抽取是一种关系抽取方法,现有方法主要采用多实例学习,在具有相同实体对的样例包上进行关系抽取。但是,包级方法只能缓解却并不能完全解决错误标签问题。基于此,文中首先分析了干净数据和噪声数据的分布,提出了一种新的自适应损失函数;在此基础上,提出了一种基于自适应损失函数的句子级远程监督关系抽取方法。在公开数据集NYT-10以及基于TACRED的合成数据集上的实验结果表明:文中提出的方法优于文献中的方法,能够更有效的区分错误标签噪声样例和干净样例,提高了句子级远程监督关系抽取的准确率。
关键词:自然语言处理;信息抽取;关系抽取;远程监督;噪声分离;噪声标注;负训练;自适应损失函数
概述
关系抽取(relation extraction, RE)是信息抽取的主要子任务之一,旨在从一段文本中抽取出两个实体名词之间存在的关系信息,将半结构化、非结构化文本数据转化为结构化的实体关系三元组以用于各种下游任务中,如知识图谱的构建与补齐、问答系统、机器翻译等$^{[1]}$。为解决人工标注大规模数据集成本过高的问题,Mintz等$^{[2]}$提出了远程监督关系抽取(distance relation extraction)的方法。为缓解远程监督带来的错误标签噪声问题,Riedel等$^{[3]}$ 提出多实例学习方法(multi-instance learning, MIL)进行包级别的关系抽取。但采用包级关系抽取会导致无法明确与包中每个句子映射的句子级标签,限制了在一些需要句子级关系的下游任务中的应用$^{[4-5]}$。之后的几项研究$^{[6-7]}$也验证了包级关系抽取在句子级评估上的性能不足。因此,仍然需要研究有效的句子级降噪方法来解决远程监督数据集中的错误标签噪声问题。2021年,Ma等$^{[8]}$提出了一种句子级的远程监督关系抽取框架——SENT,采用负训练$^{[8-9]}$ (negative training, NT)方式有效降低了模型对噪声数据的过度拟合,且在一定程度上分离了噪声数据和干净数据。但SENT方法降噪性能的收敛速度较慢,需要经过多轮模型迭代训练才能达到一个较好的降噪效果;此外,SENT方法对噪声与干净数据的分离距离仍然不足,降噪阈值邻域区间仍存在大量干净数据和噪声数据混杂在一起,导致降噪性能不稳定。如果能加大噪声数据和干净数据的分离距,将噪声数据和干净数据分别集中在低置信度区间和高置信度区间,减少中部区间的样本数量,则可降低阈值参数设置的敏感度,提升模型降噪性能的稳定性和收敛速度。本文根据噪声数据和干净数据的分布规律,提出了一种新的自适应加权损失函数ANTLoss(self-adaptive negative training loss),该损失函数可以减小噪声数据和干净数据的学习权重,进而抑制模型对噪声数据和简单干净数据的拟合,使其将更多的注意力集中在中部区间混杂难分的数据上,将噪声数据与干净数据更大程度的分离开来。在此基础上,本文提出了一种基于自适应损失函数的句子级远程监督关系抽取算法。实验结果表明,本文方法性能优于文献中的方法,在降噪与分类性能方面都有所提升。本文的主要工作贡献如下:
(1) 在SENT框架的基础上对负训练损失函数进行改进,提出了一种新的可以根据训练样本概率分布变化进行动态调整的自适应加权损失函数。该方法与模型无关,可应用于其他存在错误标签噪声的任务中。
(2) 提出了一种基于自适应损失函数的句子级远程监督关系抽取算法。
1 相关工作
Mintz等$^{[2]}$在 2009 年提出了远程监督关系抽取方法,用于解决人工标注大规模数据集成本过高的问题。该方法基于已有的关系知识库,将知识库中的实体对与大规模未标注的语料库进行自动对齐,生成有标注的训练数据集。其基于这样一种假设:对于知识库中已存在的一个实体对 具有关系 ,则外部语料中任何提及实体对 的句子都具有关系 。但是,该方法仅关注文本和知识库中是否有相同的实体对,忽视了实体对在不同上下文语境下可能会有不同的关系表现,不可避免地带来了错误标签噪声问题。为缓解该问题,Riedel等$^{[3]}$将假设松弛到“关系至少出现一次”的程度,进而提出了多实例学习方法$^{[10-11]}$,用包级关系抽取来缓解噪声问题。包级关系抽取将具有相同实体对的样例打包为一个句子包,每个句子包具有一个包级标签,模型训练和测试都在包级别上进行。基于多实例学习的降噪研究主要分为两种:(1) 软降噪方法,通过注意力机制为包内、包间句子分配不同权重以降低噪声句子的影响力$^{[12-14]}$或为样本打上软标签$^{[15]}$;(2) 硬降噪方法,使用强化学习或对抗生成网络直接从包中去除噪声句子$^{[7,16]}$。
Shang等$^{[17]}$认为之前大多数降噪方法所忽略的噪声样例并非无用的数据,而是缺乏正确的关系标签。如果能为噪声样例打上正确的关系标签,则既能减少噪声句子的负面影响,又能增加有用训练数据的数量。基于此,文$^{[17]}$提出了一种基于深度聚类网络的降噪模型,可用于噪声数据的重新标注。该方法是一个包级降噪方法,虽然能在一定程度上缓解噪声问题,但仍无法明确与包中每个句子映射的句子级标签。如图1所示,对于包级样例,我们无法确定其包级标签是属于“Place_of_birth”还是“Employee_of”,也无法明确与每一句话对应的句子标签;此外,对于“Obama was back to the United States”这句话,其实际对应的真实关系是“Lived_in”,但该关系并不存在于包级标签的关系集合中。因此,此后的一些工作开始进行句子级的降噪研究。Jia等$^{[6]}$提出了一种基于注意力正则的句子级降噪框架。Ma等$^{[8]}$提出了一种基于负训练的句子级降噪框架来对噪声数据进行分离并重新标注,达到了目前句子级降噪的最好效果。
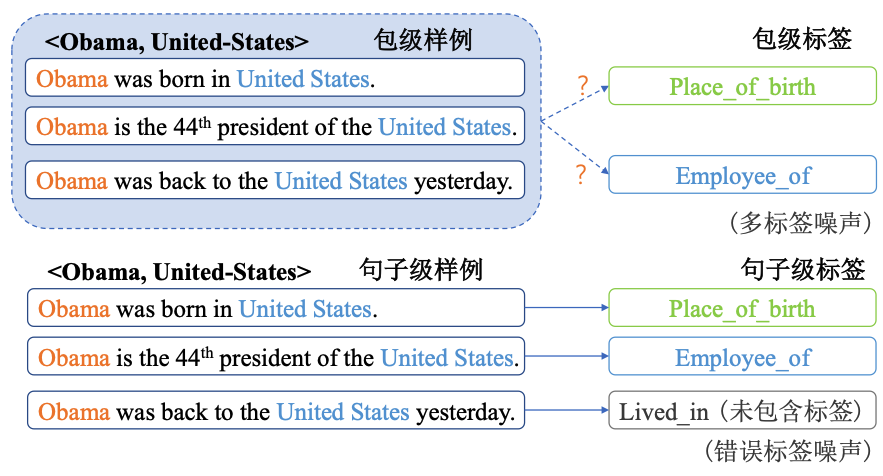 图1 包级标签与句子级标签对比
图1 包级标签与句子级标签对比
Fig.1 Comparison of bag-level label and sentence-level label
在远程监督中,也可通过使用动态损失函数来进行降噪。Lin等$^{[18]}$于2017年提出Focal Loss,Tan等$^{[19]}$在其基础上提出了基于动态Focal Loss的文档级关系抽取模型。彭正阳等$^{[20]}$提出了一种基于动态损失函数的包级远程监督关系抽取模型,但该方法存在训练初期不稳定的问题。
2 句子级远程监督关系抽取
在本任务中,我们将句子级输入样例表示为 $S^∗= { (s_1,y^∗_1),\dots ,(s_N,y^∗_N) }$,每个句子$s_i$包含一个实体对$(e_1,e_2)$和与之对应的标签$y^∗_i\in \mathbb{R}={1,\dots,C}$,$C$是关系类别个数。由于$y^∗$是来自于远程监督数据集中的包级标签,很显然是带有噪声的,$S^*$是一个带有噪声的数据集。我们将没有噪声的真实数据集表示为 $S={(s_1,y_1),\dots ,(s_N,y_N)}$。
本文的研究工作在SENT框架的基础上展开。如图2所示,为实现句子级的远程监督关系抽取,需要经过如下步骤:
(1)在数据集$S^∗$上进行NT训练,得到一个关系分类器;
(2)执行噪声过滤过程,从数据集$S^∗$中划分出噪声数据集$S^∗_n= {(s_i, y^∗i) | y^∗i \ne y_i}$;
(3)执行重新标注过程,对$S^∗n$进行重新标注得到$S^∗{n,relabeled} = {(s_i, y_i^∗) | (s_i, y^∗i) ∈ S^∗n}$,以及精炼后的数据集$S^∗{refined} = (S^∗ \setminus S^∗n ) \cup S^∗{n,relabeled}$;
(4)使用精炼后的$S^∗{refined}$迭代执行NT 训练、噪声过滤、重新标注过程,直到精炼后的数据集$S^∗{refined}$接近于真实数据集$S$;
(5)在精炼后的数据集$S^∗{refined}$上执行PT训练,得到最终的关系分类器。
本文工作主要在于NT训练中所使用的ANTLoss函数,该损失函数包含三个关键环节:正态加权、权重自适应调整和随机加权。
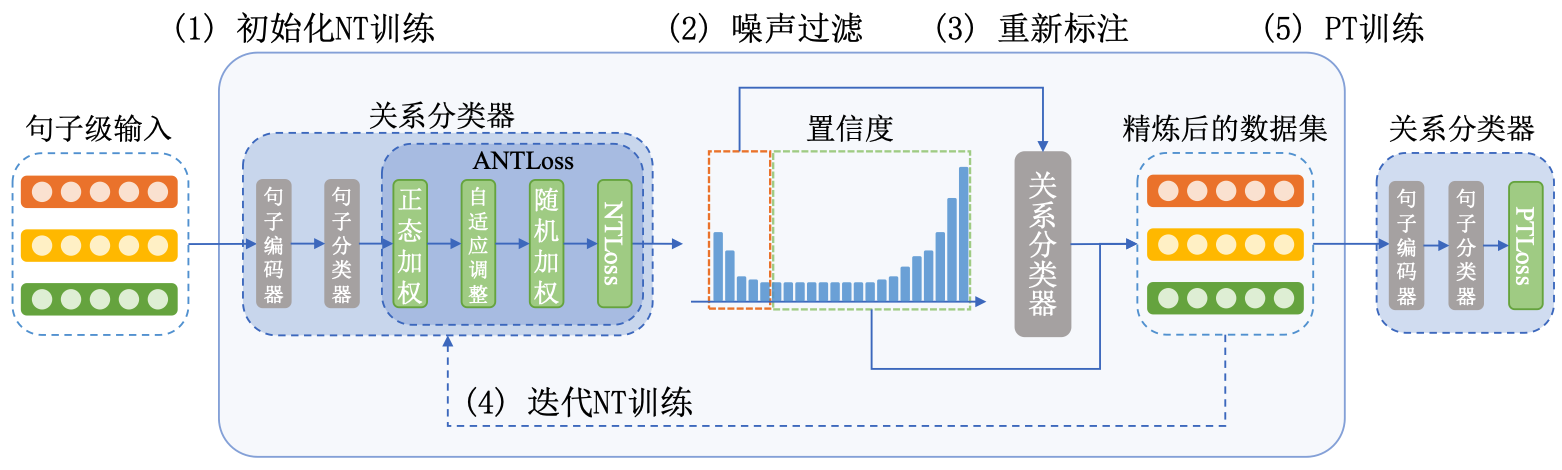 图2 句子级关系抽取降噪框架
图2 句子级关系抽取降噪框架
Fig.2 Sentence-level relation extraction denoise framework
2.1 加权损失函数
传统的分类模型训练通常采用正训练(positive training, PT),即“输入的句子属于这个标签”。对于输入句子$s$有标签$y^∗\in \mathbb{R}={1,\dots,C}$,其中,$C$ 维 one-hot 向量表示为$y \in {0, 1}^C$ 。 $p = f(s)$ 表示将句子$s$输入关系分类器 $f(·)$ 所得到的概率向量。以交叉熵损失函数为例,正训练损失函数PTLoss定义为:
$$L_{PT}(f,y^*)=-\sum^C_{j=1}y_j\log(p_j) \qquad(1)$$
其中, $p_j$ 表示第 $j$ 个类的概率,随着损失的减小, $p_j \to 1$。
与正训练思路相反,在负训练(NT)中模型要预测“输入句子不属于这个标签的互补标签”。对于带有标签 $y^∗ \in \mathbb{R}$ 的句子 $s$,我们在 $y^∗$ 之外的标签集合中随机采样以构造其互补标签 $\bar{y^∗} \in \mathbb{R}\setminus{y^∗}$。同样以交叉熵损失函数为例,负训练损失函数NTLoss定义为:
$$L_{NT}(f,y^∗)=-\sum_{j=1}^{C}\bar{y_j}\log (1-p_j) \qquad (2)$$
在这里,(2)式旨在降低模型对互补标签的预测概率,随着损失的减小,$p_j\to 0$。
Kim等$^{[9]}$ 的研究证明,当训练集存在错误标签噪声时,使用NT训练以一种迂回的方式进行学习,干净样本的互补标签能带入比噪声样本的互补标签更多的有效信息,模型会以更快的速度去拟合干净数据。Ma等$^{[8]}$ 的实验结果也证明,在远程监督数据集上,使用PT训练时干净数据和噪声数据被模型无差别的进行学习,置信度都在同步增加。与之相反,使用NT训练时噪声数据的置信度远低于干净数据的置信度。
图 3为PT训练和NT训练在噪声数据集Noisy-TACRED上的效果对比。经过NT训练以后,噪声数据主要分布在低置信度区间,干净数据主要分布在中、高置信度区间。
 图3 Noisy-TACRED上正训练与负训练效果对比
图3 Noisy-TACRED上正训练与负训练效果对比
Fig.3 Comparison of PT and NT results on Noisy-TACRED
本文采用一个服从正态分布的权重函数来对NTLoss进行加权,该权重函数公式如下:
$$W(p)=\exp(-\frac{(p-\mu)^2}{2\sigma^2})^\gamma \qquad(3)$$
其中,$p$ 是样本预测概率,$\mu$、$\sigma$是权重函数的两个超参数,$\gamma$ 用于控制权重函数的抑制力度。当$\gamma \to 0$时,权重函数的抑制力度会逐渐减小,最终退化为原始的损失函数。加权以后的负训练损失函数如下:
$$L_{NT}(f,y^*)=-\sum_{j=1}^{C} W(p_j)\cdot\bar{y_j}\log (1-p_j) \qquad(4)$$
图4为加权损失函数的函数曲线,可见该损失函数低置信度区间和高置信度区间都被拉低,中部保持不变,这样将会抑制模型对高、低置信度区间简单干净数据和噪声数据的拟合,使模型将更多的注意力集中在中部难以区分的数据上。
 图4 加权损失函数曲线
图4 加权损失函数曲线
Fig.4 Curve of weighted loss function
2.2 自适应权重
如图5所示,在相同学习步数下,模型对不同类的拟合程度是不同的。如果全局使用统一的权重函数进行加权,则可能会损害数据分布。在一些拟合相对较慢的类别中,一些本应该被正常学习的样例会由于整体置信度偏低而受到抑制。
 图5 相同学习步数下不同类的拟合程度
图5 相同学习步数下不同类的拟合程度
Fig.5 Fitting degree of different classes under the same number of learning steps
因此,我们进一步提出一种自适应权重函数,根据各类数据的拟合情况来动态的调整权重,自动适应各类的概率分布。假设类$j$的第$i$个样例概率为$p^i_j\in(0,p^h_j)$ ,其中 $p^h_j=\max^{N_j}_{i=1}{P^i_j}$ 是第 $j$ 类样例中概率的最大值,$N_j$ 为 $j$ 类样本的个数。第 $j$ 类的自适应权重函数为:
$$W_A(p_j)=W(p_j)\cdot \frac{1}{p^h_j} \qquad(5)$$
其中,$W(p_j)$为全局权重函数(3)式。
2.3 随机加权
越早进行加权抑制,则模型对噪声数据的拟合程度就越低,更多的噪声数据将会被抑制在低置信度区间。但过早的施加权重同样会导致模型对仍处于低置信度区间的干净数据欠拟合,如图6(a)所示,大量干净数据被困于低置信度区间无法得到模型有效的学习。由于模型对干净数据的拟合速度要比噪声数据更快,因此在低置信度区间以一个较小的概率随机使一部分数据能够被正常学习,则既能使干净数据逃离低置信度区间,又不会让模型过多的拟合噪声数据;而当训练进入后期,低置信度区间剩下的主要都是噪声数据,此时再进行随机正常学习只会加大模型对噪声数据的拟合,应当加大对低置信度区间数据的抑制。基于此,本文在(5)式的基础上提出了一种随机加权权重函数:
$$W_R(P_j)=\begin{cases}
1, & p_j<t^p\ \land \ r_j<T^r\ \land \ e\le T^e \
0, & p_j<t^p\ \land \ r_j<T^r\ \land \ e> T^e \
W_A(P_j), & 其他
\end{cases} \qquad(6)$$
其中 $t_j^p=T^p\cdot(p_j\setminus p^h_j)$ 是划分低置信度区间的阈值, $T^p$ 是全局阈值, $t^p_j$ 会根据各个类的拟合程度自适应的调整低置信度区间范围。 $r_j\in[0,1]$ 是对应于 $p_j$ 的一个随机数,$T^r$ 为全局阈值。 $e$ 为当前训练的epoch轮数,$T^e$ 为全局阈值。当 $p_j < t^p $ 时,样本处于低置信度区间,此时若 $e\le T^e$ 表示训练处于初期阶段,为防止干净数据欠拟合,以 $T^r$ 的概率随机将其权重置为1,使其能够被正常学习;相反,若 $e>T^e$,则表示进入训练后期,此时干净数据已经处于中高置信度区间,低置信度区间主要为噪声数据,以 $T^r$ 的概率随机将其权重置为0,加大对噪声样本的抑制程度;其他情况,则采用 $W_A(p_j)$ 函数进行加权。使用随机加权后最终的损失函数如下:
$$L_{ANT}(f,y^*)=-\sum_{j=1}^{C} W_R(p_j)\cdot\bar{y_j}\log (1-p_j) \qquad(7)$$
如图6(b)所示,可以看到使用随机加权损失函数以后,低置信度区间不再滞留大量干净数据,而噪声数据则被更多的抑制在了该区间范围内,分布于中部区间的数据也大幅降低。
 图6 训练早期施加权重损失的效果对比
图6 训练早期施加权重损失的效果对比
Fig.6 Comparison of using weighted-loss in early stage
3 实验与结果分析
实验分为两个部分,分别在NYT-10$^{[3]}$和TACRED$^{[21]}$数据集上进行。实验采用与Ma等$^{[8]}$相同的句子级评估指标,直接计算单个样例的精度 、召回率和 F1 值。
3.1 基线模型
关系抽取中常用的文本编码器有CNN$^{[22]}$、PCNN$^{[23]}$、BiLSTM$^{[24]}$和BERT$^{[25]}$,以及在此基础上的变体BiLSTM+ATT$^{[26-27]}$、BiLSTM+BERT $^{[26]}$等。
PCNN+SelATT$^{[12]}$:一种包级关系抽取模型,利用自注意力机制来减轻噪声数据的影响。
PCNN+RA_BAG_ATT$^{[13]}$:一种包级关系抽取模型,同时在包内和包间使用注意力机制来减轻噪声的影响。
CNN+RL1$^{[16]}$:一种基于强化学习的包级方法。 与 CNN+RL2 不同的是,它们将过滤后的噪声数据重新分配到负样本中。
CNN+RL2$^{[7]}$:一种句子级关系抽取模型,使用强化学习来联合训练样例选择器和 CNN 分类器。
ARNOR$^{[6]}$:一种基于注意力正则的句子级降噪框架,迫使模型去学习语义模式而不仅仅是关注实体对,使模型更具解释性,并以此来选择可靠的样例。
SENT$^{[8]}$:一种句子级降噪框架,使用负训练、噪声过滤与重新标记、迭代训练的方法,有效的将噪声数据从训练数据中分离,并重新标记用以训练。它是目前句子级别最先进的方法。
3.2 实验细节
实验中,除ANTLoss以外的参数均保持与SENT源码一致,仅对ANTLoss参数进行网格搜索调参,具体参数设置如表1所示。
| 参数 | 值 |
|---|---|
| $\mu$ | 0.4 |
| $\sigma$ | 0.5 |
| $\gamma$ | 1 |
| $T^p$ | 0.35 |
| $T^r$ | 0.25 |
| $T^e$ | 7 |
Table 1 Method parameters
在具体实现中,本文在每一次epoch训练结束后同步更新 $p^h_j$ ,作为下一轮epoch训练中损失函数自适应调整的参数。因此,ANTLoss至少需要经过一个epoch之后才能生效。由于采用前一轮历史 $p^h_j$ 来近似当前轮的最大值,可能出现缩放后权重大于1的情况,对此我们将大于1的权重置为1。
在消融实验中,对于没有使用随机加权的损失函数需要经过7个epoch的预热训练,待干净数据大部分进入中、高置信度区间后才开始生效。
3.3 NYT-10上的效果
第一部分实验在NYT-10上开展,以验证本方法在句子级远程监督数据集上的有效性。NYT-10 最早是由Riedle等提出一个远程监督数据集,在之后的研究中被广泛使用。Jia等$^{[6]}$在其基础上进行人工精标,发布了一个句子级的关系抽取测试集以及降噪评估测试集。
3.3.1 句子级评估
表2展示了使用ANTLoss以后的SENT模型与其他基线模型在句子级评估上的效果对比,我们将模型运行了三次,计算均值与标准差。从表2可以看出:本文模型相比其他方法准确率提升了5.12%,F1值提升了2.36%,说明本方法在分类性能提升上的有效性。
| 验证集 | 测试集 | |||||
|---|---|---|---|---|---|---|
| 方法 | 准确率 | 召回率 | F1值 | 准确率 | 召回率 | F1值 |
| CNN | 38.32 | 65.22 | 48.28 | 35.75 | 64.54 | 46.01 |
| PCNN | 36.09 | 63.66 | 46.07 | 36.06 | 64.86 | 46.35 |
| BiLSTM | 36.71 | 66.46 | 47.29 | 35.52 | 67.41 | 46.53 |
| BiLSTM+ATT | 37.59 | 64.91 | 47.61 | 34.93 | 65.18 | 45.48 |
| BERT | 34.78 | 65.17 | 45.35 | 36.19 | 70.44 | 47.81 |
| BiLSTM+BERT | 36.09 | 73.17 | 48.34 | 33.23 | 72.70 | 45.61 |
| PCNN+SelATT | 46.01 | 30.43 | 36.64 | 45.41 | 30.03 | 36.15 |
| PCNN+RA_BAG_ATT | 49.84 | 46.90 | 48.33 | 56.76 | 50.60 | 53.50 |
| CNN+RL1 | 37.71 | 52.66 | 43.95 | 39.41 | 61.61 | 48.07 |
| CNN+RL2 | 40.00 | 59.17 | 47.73 | 40.23 | 63.78 | 49.34 |
| ARNOR | 62.45 | 58.51 | 60.36 | 65.23 | 56.79 | 60.90 |
| SENT (BiLSTM) | 66.71 $_{\pm 0.30}$ | 57.27 $_{\pm 0.30}$ | 61.63 $_{\pm 0.29}$ | 71.22 $_{\pm 0.58}$ | 59.75 $_{\pm 0.62}$ | 64.99 $_{\pm 0.34}$ |
| SENT (BiLSTM) +ANTLoss | 72.04 $_{\pm 0.56}$ | 57.06 $_{\pm 0.69}$ | 63.68 $_{\pm 0.29}$ | 76.34 $_{\pm 0.68}$ | 60.26 $_{\pm 0.29}$ | 67.35 $_{\pm 0.19}$ |
Table 2 Sentence level evaluation results on nyt-10 test set (%)
3.3.2 降噪效果
本文方法通过直接提升模型的降噪性能进而间接提升模型的关系抽取性能,因此降噪效果是衡量该方法好坏的直接指标。降噪实验结果如表3和图7所示。
根据表3,文中方法在F1上提升了0.58%。通过分析降噪测试集各类的降噪效果,发现数据量较大的类别中F1已经达到0.9以上,而数据量较少的类别F1普遍更低,从概率分布可发现该类别样本通常整体处于欠拟合状态,并不适合通过加权抑制来进行降噪处理。因此,影响F1值的是数据量较少的类别,加上ANTLoss以后有所提升,但是整体提升空间不大。
| 方法 | 准确率 | 召回率 | F1值 |
|---|---|---|---|
| CNN+RL | 40.58 | 96.31 | 57.10 |
| ARNOR | 76.37 | 68.13 | 72.02 |
| SENT (BiLSTM) | 80.00 | 88.46 | 84.02 |
| SENT (BiLSTM)+ANTLoss | 80.76 | 88.78 | 84.58 |
Table 3 Evaluation results on nyt-10 denoise test set (%)
 图7 各迭代次数模型降噪性能比较
图7 各迭代次数模型降噪性能比较
Fig.7 Comparison of noise reduction performance of each iteration model
如图7所示,从模型各迭代训练次数的降噪效果来看,SENT的方法需要经过14次迭代训练才能达到0.8以上,且过程中有较大波动;而文中方法仅需经过2次迭代,速度提升7倍,效果也更稳定。因为ANTLoss在将更多的噪声数据压制在低置信度区间的同时拉开了噪声数据和干净数据之间的距离,降低了阈值设置的敏感度,模型在收敛速度得到提升的同时性能也更为稳定。
3.4 Noisy-TACRED上的效果
第二部分实验在斯坦福大学开源的一套人工精标的关系抽取数据集TACRED 上开展,参照Ma等$^{[8]}$的构造方法,合成了一个包含30%噪声的Noisy-TACRED数据集,以更直观的展示本方法各组件的降噪效果。
由于本框架与文本编码模型无关,为更明显的体现本方法改进后的效果,此处选用关系抽取中最为经典的PCNN模型作为编码器,在初始化NT训练中对ANTLoss各模块进行消融实验。
3.4.1 P@LastN准确率
类似之前工作中所使用的P@N指标,本文采用P@LastN来计算概率最小的N个样本中模型的降噪准确度。
如图8所示,当训练轮数超过12轮以后,原始的SENT方法降噪精度迅速下降,在P@Last500中,ANTLoss损失函数基本能稳定不变,在P@Last1000与P@Last2000中下降的速度也要明显慢于原始方法,可见ANTLoss可以有效提升模型对噪声数据的抗拟合性能,将更多的噪声抑制在低置信度区间。从图中还可以观察到,随着样本量增加,前三条曲线均有不同程度的波动,ANTLoss相较更为稳定。
 图8 P@LastN曲线
图8 P@LastN曲线
Fig.8 Curve of P@LastN
如表4所示,分别统计了500、1000、2000个样本中模型降噪准确率的最大值并求其均值,ANTLoss各项指标均较先前的方法有所提升,其中均值较原始SENT方法提升1.5%。
| 方法 | 500 | 1000 | 2000 | 均值 |
|---|---|---|---|---|
| SENT(PCNN) | 96.00 | 89.90 | 67.75 | 84.55 |
| +加权 | 96.80 | 89.80 | 68.05 | 84.88 |
| +动态加权 | 96.60 | 88.50 | 69.20 | 84.76 |
| +动态随机加权 | 96.80 | 90.90 | 70.45 | 86.05 |
Table 4 P@LastN Accuracy comparison(%)
3.4.2 固定阈值下的降噪效果
在真实远程监督数据集上,由于不清楚噪声数据的具体数据量,往往通过设置阈值的方式来过滤噪声数据。图 9展示了随着模型迭代轮数的增加,在35%阈值下过滤噪声的查准率、召回率以及F1值。
 图9 固定阈值下降噪效果曲线
图9 固定阈值下降噪效果曲线
Fig.9 Curve of denoising result with fixed threshold
从图9可以看出,使用加权损失函数以后过滤噪声的召回率在训练后期相较于原始方法大幅度提升,查准率也略有提升。由于ANTLoss采用了随机加权方法,在训练前期干净数据能快速的逃离阈值过滤区间,因此前期降噪查准率提升更为迅速;而在训练后期噪声数据权重被随机置为0,大幅度降低了模型对噪声数据的拟合程度,使得更多的噪声数据能滞留于阈值过滤区间之内,因此后期召回率下降幅度减小。
表5给出了35%阈值下四种方法降噪F1值的最大值。从表5可以看出:随着损失函数的逐步优化,降噪性能逐步提升,最终ANTLoss相较于原始方法提升了3.28%。
| 方法 | F1 |
|---|---|
| SENT(PCNN) | 71.92 |
| +加权 | 72.52 |
| +动态加权 | 74.70 |
| +动态随机加权 | 75.20 |
Table 5 Comparison of denoise effect with fixed threshold(%)
3.4.3 噪声样本和干净样本的分离率
噪声与干净数据分离率越大,则降噪阈值敏感度越低,模型降噪性能越稳定。首先,分别计算所有噪声和干净数据的平均置信度;然后,计算其差值作为噪声和干净数据的分离率来对模型进行评估,实验结果如图10所示。
 图10 噪声分离率曲线
图10 噪声分离率曲线
Fig.10 Curve of noise separation rate
从图10可以看出,本文方法对干净数据的平均置信度有所提升,同时大幅减小了噪声数据的平均值信度。由于采用了随机加权损失,ANTLoss从训练的第二个epoch就开始生效,而未使用随机加权的损失函数需要经过7个epoch的预热训练才能开始生效,且后期噪声抗拟合性能相对更弱。最终的ANTLoss噪声分离率曲线稳定且完全包裹住了前面的方法。
表6统计了各方法噪声分离率的最大值,容易看出噪声分离率随着方法优化在逐步提升,最终相较原始模型提升了11.51%,说明了本文方法在提升噪声分离率上的有效性。
| 方法 | 分离率 |
|---|---|
| SENT(PCNN) | 45.06 |
| +加权 | 47.61 |
| +动态加权 | 48.41 |
| +动态随机加权 | 56.57 |
Table 6 Comparison of noise separation rate(%)
4 结束语
本文通过对干净、噪声样本概率分布进行分析,提出了一种自适应加权损失函数,可以进一步将噪声数据抑制在低概率区间,并有效的拉开了噪声数据和干净数据之间的距离。基于此,提出了一种句子级远程监督关系抽取方法,用于解决远程监督数据集中的错误标签噪声问题。实验结果表明,本方法在句子级远程监督关系抽取的降噪和分类性能上相较之前的方法都有所提升。
参考文献
[1] 张涛, 贾真, 李天瑞, 等. 基于知识库的开放领域问答系统[J]. 智能系统学报, 2018, 13(4): 557–563.
[2] MINTZ M, BILLS S, SNOW R, et al. Distant supervision for relation extraction without labeled data[C]// Joint Conference of ACL and AFNLP. 2009: 1003-1011.
[3] RIEDEL S, YAO L, MCCALLUM A. Modeling relations and their mentions without labeled text[C]// Joint European Conference on Machine Learning and Knowledge Discovery in Databases. 2010: 148-163.
[4] YAO X, VAN DURME B. Information extraction over structured data: Question answering with freebase[C]// Association for Computational Linguistics. 2014: 956-966.
[5] XU K, REDDY S, FENG Y, et al. Question answering on freebase via relation extraction and textual evidence[C]// Association for Computational Linguistics. 2016: 2326-2336.
[6] JIA W, DAI D, XIAO X, et al. ARNOR: Attention Regularization based Noise Reduction for Distant Supervision Relation Classification[C]// Association for Computational Linguistics. 2019: 1399-1408.
[7] FENG J, HUANG M, ZHAO L, et al. Reinforcement learning for relation classification from noisy data[C]// AAAI Conference on Artificial Intelligence, 2018, 32(1): 5779-5786.
[8] MA R T, GUI T, LI L Y, et al. SENT: Sentence-level Distant Relation Extraction via Negative Training[C]// Joint Conference on Association for Computational Linguistics and International Natural Language Processing. 2021: 6201-6213.
[9] KIM Y, YIM J, YUN J, et al. Nlnl: Negative learning for noisy labels[C]// IEEE/CVF International Conference on Computer Vision. 2019: 101-110.
[10] HOFFMANN R, ZHANG C, LING X, et al. Knowledge-based weak supervision for information extraction of overlapping relations[C]// Association for Computational Linguistics: Human Language Technologies. 2011: 541-550.
[11] SURDEANU M, TIBSHIRANI J, NALLAPATI R, et al. Multi-instance multi-label learning for relation extraction[C]// Empirical Methods in Natural Language Processing and Computational Natural Language Learning. 2012: 455-465.
[12] LIN Y, SHEN S, LIU Z, et al. Neural relation extraction with selective attention over instances[C]// Association for Computational Linguistics. 2016: 2124-2133.
[13] YE Z X, LING Z H. Distant supervision relation extraction with intra-bag and inter-bag attentions[C]// Association for Computational Linguistics: Human Language Technologies.2019: 2810-2819.
[14] LI Y, LONG G, SHEN T, et al. Self-Attention Enhanced Selective Gate with Entity-Aware Embedding for Distantly Supervised Relation Extraction[C]// AAAI Conference on Artificial Intelligence, 2020, 34(5): 8269-8276.
[15] LIU T, WANG K, CHANG B, et al. A soft-label method for noise-tolerant distantly supervised relation extraction[C]// Empirical Methods in Natural Language Processing. 2017: 1790-1795.
[16] QIN P, XU W, WANG W Y, Robust distant supervision relation extraction via deep reinforcement learning[C]// Association for Computational Linguistics. 2018: 2137-2147.
[17] SHANG Y, HUANG H Y, MAO X L, et al. Are noisy sentences useless for distant supervised relation extraction?[C]// AAAI Conference on Artificial Intelligence, 2020, 34(05): 8799-8806.
[18] LIN T Y, GOYAL P, GIRSHICK R, et al. Focal loss for dense object detection[C]// IEEE International Conference on Computer Vision. 2017: 2980-2988.
[19] TAN Q, HE R, BING L, et al. Document-Level Relation Extraction with Adaptive Focal Loss and Knowledge Distillation[C]// Association for Computational Linguistics.2022:1-10.
[20] 彭正阳, 吕立, 于碧辉. 基于动态损失函数的远程监督关系抽取[J]. 小型微型计算机系统, 2021, 42(2): 251-255.
[21] ZHANG Y, ZHONG V, CHEN D, et al. Position-aware Attention and Supervised Data Improve Slot Filling[C]// Empirical Methods in Natural Language Processing (EMNLP 2017). 2017: 35-45.
[22] ZENG D, LIU K, LAI S, et al. Relation classification via convolutional deep neural network[C]// Computational Linguistics: Technical Papers. 2014: 2335-2344.
[23] ZENG D, LIU K, CHEN Y, et al. Distant supervision for relation extraction via piecewise convolutional neural networks[C]// Empirical Methods in Natural Language Processing. 2015: 1753-1762.
[24] ZHANG S, ZHENG D, HU X, et al. Bidirectional long short-term memory networks for relation classification[C]// Language, Information and Computation. 2015: 73-78.
[25] DEVLIN J, CHANG M W, LEE K, et al. Bert: Pre-training of deep bidirectional transformers for language understanding[C]// Association for Computational Linguistics: Human Language Technologies. 2018: 4171-4186.
[26] ZHANG Y, ZHONG V, CHEN D, et al. Position-aware attention and supervised data improve slot filling[C]// Empirical Methods in Natural Language Processing. 2017: 35-45.
[27] 张勇, 高大林, 巩敦卫, 等. 用于关系抽取的注意力图长短时记忆神经网络[J]. 智能系统学报, 2021, 16(3): 518–527.

