$Yu-Ming Shang^{1,2,4}, He-Yan Huang^1, Xian-Ling Mao^1, Xin Sun^1, Wei Wei^3$
$^1 计算机科学学院, 北京理工大学, 北京, 中国 $
$^2 中电大数据研究院有限公司, 贵阳, 中国,550022 $
$^3 华中科技大学, 湖北, 中国 $
$^4 贵阳大数据应用提高政府治理能力国家工程实验室, 中国, 550022 $
${ymshang, hhy63, maoxl, sunxin}@bit.edu.cn, Weiw@hust.edu.cn$
摘要
噪声标签问题一直是远程监督关系抽取的主要障碍之一。现有的方法通常认为,噪声句子是无用的,将损害模型的性能。因此,他们主要通过减少噪声句子的影响来缓解这一问题,例如应用包级选择性注意力机制或从句子包中去除噪声句子。然而,噪声标签问题的根本原因不是缺少有用的信息,而是缺少关系标签。直观地说,如果我们能够为噪声句子分配可信的标签,它们将转化为有用的训练数据,并有利于模型的性能。因此,在本文中,我们提出了一种新的远程监督关系抽取方法,该方法采用无监督的深度聚类为含噪句子生成可靠的标签。具体来说,我们的模型包含三个模块:句子编码器、噪声检测器和标签生成器。句子编码器用于获取特征表示。噪声检测器从句子包中检测噪声句子,标签生成器为噪声句子生成高置信度关系标签。大量的实验结果表明,我们的模型在一个主流的基准数据集上优于最先进的基线,并且确实可以缓解噪声标签问题。
概述
关系抽取是自然语言处理(NLP)中的一项关键任务,它被定义为从非结构化文本中提取结构化关系。关系提取的主要挑战之一是缺少大规模的手动标记数据。因此,Mintz等人(2009)提出了远程监督,以自动构建训练数据。远程监控的假设是,如果两个实体$(e_1,e_2)$在知识图中具有关系$r$,那么提及这两个实体的任何句子都可能表示关系$r$。
显然,这种假设太强,会导致噪声标签问题。因为它只关注文本和知识图中实体的存在,而不能识别句子和关系之间的一对一映射。例如,如表1所示,$(Barack\ Obama,president\ of, United\ States)$ 是知识图中的一个关系三元组。远程监督将把所有包含$[Barack\ Obama]{e_1}$和$[United\ States]{e_2}$的句子视为“$president\ of$”关系。因此,表达关系“$born\ in$”的第一个句子被错误地贴上“$president\ of$”关系的标签,并成为句子包中一个噪声句子。
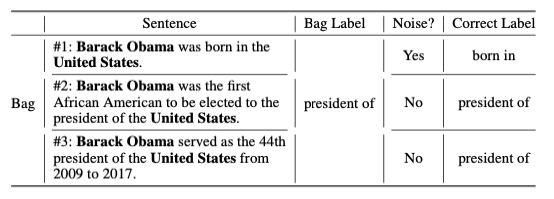
表1:远程监督注释的句子包示例。“$Yes$”和“$No$”表示每个句子是否是一个噪声句子。“$Correct\ Label$”指每个句子中表示的实体对之间的真实关系。
以前的研究通常采用多实例学习(MIL)框架来解决这个问题(Riedel、Yao和Mccallum,2010)。在此框架中,训练和测试过程在句子包级别进行,其中句子包包含提及相同三元组 $(e_1、r、e_2)$ 的所有句子。现有的MIL研究大致分为两类:一类是软决策方法,它倾向于对句子进行软加权,以减少噪声句子的影响(Lin等人2016;Yuan等人2019a;Yuan等人2019b;Ye和Ling 2019)。另一种是硬决策方法,试图从句子包中去除噪声句子以消除其影响(Zeng等人2015;Feng等人2018;Qin,Xu和Wang 2018)。
然而,以前的去噪方法忽略了噪声标签问题的根本原因——缺乏正确的关系标签。为了填补这一空白,我们试图从噪音句子使用的角度解决这个问题,即纠正错误的标签。如表1所示,“$Barack\ Obama\ was\ born\ in\ the\ United\ States$”是句子包中一个噪声句子。然而它确实表达了$[Barack\ Obama]{e_1}$和$[United\ States]{e_2}$之间的“$born\ in$”关系。直觉上,如果我们能够将其关系标签从“$president\ of$”更改为“$born\ in$”,它将转化为一个有用的训练实例。这种想法有两个好处:(1)减少了噪音句子的负面影响。(2) 有用的训练数据的数量增加了。
在本文中,我们提出了一种新的基于深度聚类的关系抽取模型DCRE,该模型采用无监督的深度聚类来生成含噪句子的高置信度标签。更具体地说,DCRE由三个模块组成:句子编码器、噪声检测器和标签生成器。句子编码器用于生成句子表示,并由其他两个模块共享。噪声检测器根据句子之间的匹配度和包级目标关系从句子包中选择带噪句子。得分低于某个阈值的句子将被视为噪声句子。标签生成器借助深度聚类神经网络为含噪句子生成可靠的标签。由于无监督聚类的结果可能存在误差,我们进一步利用聚类置信度作为权重来衡量损失函数。实验结果表明,我们的模型性能优于最先进的基线。我们的贡献如下:
- 与现有的包级去噪方法不同,我们的模型尝试将含噪语句转换为有用的训练数据,同时减少含噪数据并增加有用数据。
- 据我们所知,这是第一个应用无监督深度聚类的工作,以便为噪声句子获得更合适的关系标签。
- 大量实验表明,我们的模型优于最先进的基线,并能有效缓解噪声标签问题。
相关工作
本文提出了一种基于无监督深度聚类的远程监督关系抽取模型。本文的相关工作主要包括:
远程监督关系抽取
远程监控(Mintz等人 2009)旨在自动获取大规模训练数据,已成为关系提取的标准方法。然而,远程监控生成的训练数据往往含有大量的噪声句子。因此,降噪已成为远程监督关系提取的主流。根据处理含噪句子的方式,现有的去噪方法可分为三类:
第一类方法倾向于在句子或句子包上分配软权重。通过进行选择性注意力机制,模型可以更加关注高质量的句子,并减少噪音句子的影响。例如,Lin等人 (2016)采用注意机制,将不同的权重分配给每个句子,以确定包的表示。Yuan等人 (2019a)使用非独立且同分布的语义相关性来获得每个句子的权重。Yuan等人 (2019b)利用交叉关系跨包选择性注意来减少噪声句子的影响。Ye和Ling (2019)考虑包内和包间的注意力,以在句子级和包级处理噪声句子。
第二类方法试图通过硬判决从句子包中去除噪声句子。例如,Zeng等人(2015)从每个包中选择最正确的句子,忽略其他句子。Feng等人(2018)利用强化学习训练实例选择器,并从句子包中移除错误样本。Qin, Xu和Wang (2018)也使用强化学习来处理噪声句子。与(Feng等人,2018)不同,他们将噪声句子重新分配到负样本中。
与前两类不同,第三类方法在训练阶段不直接处理噪声句子。例如,Takamatsu、Sato和Nakagawa (2012)使用句法模式识别潜在的噪声句子,并在预处理阶段将其删除。Wang 等人 (2018)避免使用噪声关系标签,并使用$e_2−e_1$作为训练模型的软标签。Wu、Fan和Zhang (2019)提出了一个线性层,以获得真实标签和噪声标签之间的联系。然后,仅基于真实标签进行最终预测。
与前两类相似,本文提出的模型在训练阶段也直接处理有噪声的句子。DCRE与其他方法的主要区别在于:DCRE试图将噪声句子转换成有意义的训练数据。它可以同时减少噪声句子数量和增加有用的句子数量。
无监督深度聚类
深度聚类算法大致有两种类型:
第一类算法直接利用其他神经网络学习到的低维特征,然后运行k-means等常规聚类算法。例如,Tian等人 (2014)利用自动编码器学习特征表示,然后通过k-means获得聚类结果。
第二类尝试在端到端机制中学习特征表示和聚类。在这些方法中,深度嵌入式聚类(DEC)是一种专门的聚类技术(Xie、Girshick和Farhadi,2016)。该方法采用堆叠式自动编码器学习方法。在通过预训练获得自动编码器的隐层表示后,编码器路径通过定义的Kullback-Leibler散度聚类损失进行微调。Guo等人 (2017A)认为,定义的聚类损失会破坏特征空间,并且预训练过程过于复杂,因此它们保持解码器保持并增加重构损失。此后,基于这种深度聚类框架的算法不断增加(Ghasedi Dizaji等人,2017;Guo等人,2017b)。
我们工作中提出的深度聚类神经结构属于第二类。它利用预先训练好的句子编码器生成的特征,然后以端到端的方式联合优化特征表示和聚类。
方法
在本节中,我们将介绍我们的远程监督关系抽取方法。神经网络的结构如图1所示。它展示了处理一个句子包的过程。我们的模型包含三个主要模块:句子编码器、噪声检测器和标签生成器。在下面,我们首先给出任务定义和符号。然后,我们对这三个模块进行了详细的形式化描述。
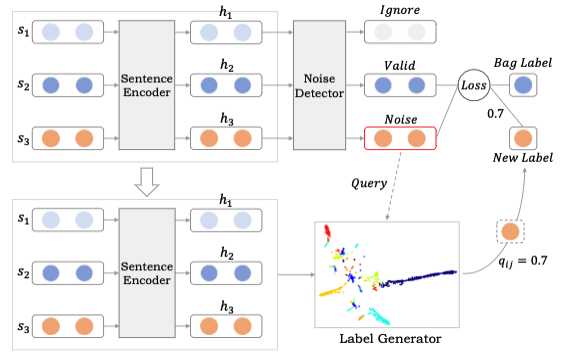
图1:DCRE的体系结构,说明了处理一个包含三个句子的句子包的过程。
任务定义和符号
我们将关系类定义为$\mathbb{R}={r_1,r_2,\dots,r_k}$,其中$k$是关系的数量。给定一组句子$\mathbb{S}_b={s_1,s_2,\dots,s_b}$,由$b$个句子和一个实体对$(e_1,e_2)$组成,表示所有句子。远程监督关系抽取的目的是根据实体对$(e_1,e_2)$预测句子包$\mathbb{S}_b$的关系$r_i$。因此,关系抽取被定义为一个分类问题。
句子编码器
在进行关系抽取时,需要将句子转换为低维向量。我们首先将一个句子转换成一个矩阵,其中包含单词嵌入和位置嵌入。然后,使用分段卷积(PCNN)(Zeng 等人 2015)层获得最终句子表示。
词表征
在句子$s$中,每个单词$w_i$首先被映射到$d_w$维单词嵌入$v_i$。本研究采用Zeng等人 (2014)提出的位置特征(PFs)来指定目标实体对,并使模型更加关注接近目标实体的单词。PFs是从当前单词到两个实体的一系列相对距离。位置嵌入$p^{e_1}_i、p^{e_2}_i$是PFs的低维向量。每个单词$w_i$的最终表示$x_i$是单词嵌入和两个位置嵌入$[v_i;p^{e_1}_i;p^{e_2}_i]$的级联。因此,输入语句表示为:
$$ X=x_1,x_2,\dots,x_{n_l} \qquad (1)$$
其中$n_l$是句子的长度。
PCNN
我们采用PCNN作为特征抽取器,它主要由一维卷积和分段最大池化两部分组成。
一维卷积是权重$W$矩阵与输入序列矩阵$X$的运算,$W$被看作是卷积的滤波器。$X_i$是与句子中第$i$个字相关联的输入向量。通常,用$x_{i:j}$表示$x_i$到$x_j$的子串,$w$表示滤波器大小。卷积是取向量$W$与句子$X$中每个$w$-gram的点积,以获得另一个序列$m_i$:
$$ m_i=W^T x_{i-w+1:i} \qquad (2)$$
$m_i$的数量为$n_l−w+1$。在我们的模型中,每个句子都用填充元素填充,使得向量$m_i$的数量等于句子$n_l$的长度。卷积结果是特征矩阵$M={M_1,M_2,…,M_{n_l}}$。特征矩阵$M_i$的数量是$n_f$,其中$n_f$是滤波器的数量。
分段最大池化用于捕获句子的结构信息。在卷积层之后,每个特征矩阵$M_i$根据两个实体的位置分为三部分${M_{i1},M_{i2},M_{i3}}$。然后,分别对这三个部分执行最大池化操作。最后的句子表示$h$是所有向量的串联:
$$ h=[p_{i1},p_{i2},p_{i3}] \qquad (3)$$
其中$p_{ik}=\max(M_{ik}),k\in {1,2,3}$。为了防止过拟合,将dropout策略(Srivastava等人,2014)应用于句子表示矩阵。
噪声检测器
噪声检测器的目的是从句子包中选择有噪声的句子,并将它们输入标签生成器。假设$H_b = {h_1, h_2, \dots, h_b}, H_b \in R^{b\times d_s}$表示句子包,$h_i$是由句子编码器生成的$d_s$-维句子表示,$b$是句子数。令$L = {l_1,l_2,\dots ,l_k},L \in R^{k\times d_s}$表示所有关系的表示。首先,采用句子表示$h_i$和包级关系标签$l_j$向量之间的简单点积作为相似度系数,如下所示:
$$ a_i=h_il^T_j \qquad (4)$$
然后,通过softmax函数在包级别对相似度系数进行归一化:
$$ a_i=\frac{\exp(a_i)}{\sum_b \exp(a_i)} \qquad (5)$$
其中,每个$a_i$对应于每个句子和目标关系之间的匹配度。它表示原始关系标签对于当前句子是正确的可能性。我们设置一个阈值$\phi$来检测含噪句子,相似度系数小于$\phi$的句子将被视为噪声样本。
然而,我们不能保证系数较高的句子没有被错误地标注。对于这种不确定性,我们的解决方案是使用当前确定的句子。在一个句子包中,我们认为得分最高的句子作为有效样本。既不确定为噪声句(得分低于$\phi$),也不确定为有效样本(得分最高)的句子将被忽略。这种操作背后的原因是:(1)如果得分最高的句子确实表达了目标关系,那么它与所表达的至少一次假设一致(Riedel、Yao和Mccallum,2010)。这一假设认为,在一个句子包中,至少有一个句子可以表达目标关系。(2)如果得分最高的句子是一个噪声样本,换句话说,包中的所有句子都是噪声样本,而句子包是一个噪声样本(Ye和Ling 2019),忽略不确定样本实际上就是去除噪声句子。在这两种情况下,重新标记高置信度噪声句子将有利于模型的性能。
标签生成器
标签生成器基于深度聚类神经网络为含噪句子提供高置信度的关系标签。设$H = {h_1, h_2, \dots, h_n}, H \in R^{n\times d_s}$表示由预先训练的句子编码器生成的所有句子的表示,而 $L = {l_1, l_2, \dots, l_k}, L \in R^{k\times d_s}$表示预先训练的关系矩阵。首先,我们将句子表示投影到关系特征空间:
$$ C=HL^T+b \qquad (6)$$
其中$b$是一个偏差。这个操作可以看作是一个注意力机制,所有关系都作为查询向量来计算关系感知的句子表示。然后,我们将$C$输入聚类层,其代表可作为训练权重的聚类中心${\mu_i}^{n_c}{i=1}$,其中$n_C$是聚类中心数。我们使用Student的t分布(Maaten和Hinton,2008)作为核函数来测量特征向量$c_i$和聚类中心$\mu_j$之间的相似性$q{ij}$:
$$ q_{ij}=\frac{(1+||c_i-\mu_j||^2)^{-1}}{\sum_j(1+||c_i-\mu_j||^2)^{-1}} \qquad (7)$$
其中,$q_{ij}$是句子表示向量$c_i$和聚类中心向量$\mu_j$之间的相似性。它也可以解释为将句子$s_i$指定为关系标签$r_j$的概率。
深度聚集的损失函数定义为Kullback-Leibler散度:
$$ L=KL(P||Q)=\sum_i\sum_j p_{ij}\log \frac{p_{ij}}{q_{ij}} \qquad (8)$$
其中$P$是目标分布。NYT-10中的关系遵循长尾分布,如图2所示。为了缓解这一数据不平衡问题,我们使用了与([Xie、Girshick和Farhadi 2016])相同的$P$,定义如下:
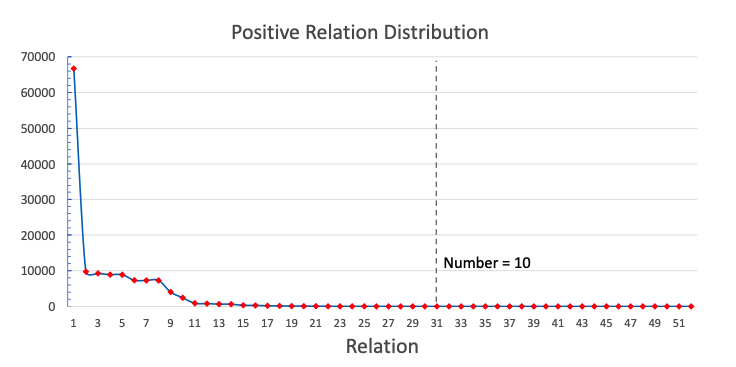
图2:NYT-10数据集中52个正关系(不包括NA)的分布。横轴表示按出现次数排序的不同关系。纵轴表示训练集中的句子数。垂直线表示id为31的关系在训练集中出现10次。
$$ p_{ij}=\frac{q^2_{ij}/\sum_i q_{ij}}{\sum_j(q^2_{ij}/\sum_i q_{ij})} \qquad (9)$$
该目标分布可以规范化每个质心的损失贡献,以防止大簇扭曲隐藏的特征空间。
注意,我们仅为正性样本生成新标签,即原始标签不是NA(无关系)的样本。因为不表示关系的句子的表示形式总是多样的,很难找到正确的标签。允许负样本重新标记将产生更多嘈杂的句子。相反,一个正性样本被重新标记为NA意味着噪声句子被删除。
比例损失函数
由于对噪声数据没有明确的监督,很难知道每个句子的聚类结果是否正确。因此,标签生成器生成的新标签可能仍然是错误的。
为了解决这个问题,如上所述,我们设置了一个阈值$\phi$并选择具有高置信度的句子作为噪声样本。此外,我们还引入了一个比例因子$q_{ij}$作为权重来缩放交叉熵(Shore和Johnson 1980)损失函数。$q_{ij}$由等式(7)获得,表示第$i$个句子属于第$j$个关系簇的概率。这个比例因子使得新标签根据其聚类置信度对模型有不同的影响。最后,目标函数定义为:
$$ J(\theta)=-\sum_{(x_i,y_i)\in \mathbb{V}} \log p(y_i|x_i;\Theta) -\lambda \sum_{(x_i,y_i)\in \mathbb{N}} q_{ij}\log p(y_j|x_i;\Theta) \qquad (10)$$
其中 $(x_i,y_i)$ 是一个训练实例,表示句子$x_i$的目标关系标签是$y_i$。$y_j$表示$x_i$的新标签是$y_j$,并且$y_j\ne y_i$。$\lambda$是平衡这两项的系数。$\mathbb{V}$为得分最高的样本,$\mathbb{N}$为噪声样本,$\Theta$为模型的所有参数。
实验
我们的实验旨在证明DCRE可以缓解噪声标签问题。在本节中,我们首先介绍数据集和评估指标。其次,我们展示了实验设置。第三,我们将我们的模型的性能与几种最先进的方法进行比较。第四,对阈值$\phi$进行了参数分析。最后,我们展示了聚类结果的一些细节。
数据和评价指标
我们在广泛使用的数据集NYT-10(Riedel、Yao和Mccallum 2010)上评估了所提出的方法,该数据集是通过将Freebase(Bollacker 等人 2008)中的关系事实与纽约时报(NYT)语料库对齐而构建的。2005-2006年的句子用于培训,2007年的句子用于测试。具体来说,训练数据中包含522611个句子、281270个实体对和18252个关系事实;测试数据中有172448个句子、96678个实体对和1950个关系事实。有53种不同的关系,包括一种特殊的关系NA,表示实体对之间没有关系。
基于之前的工作(Yuan 等人 2019b;Yuan 等人 2019a;Ye和Ling 2019),我们在进行留出法评估时评估了我们的模型和基线,并用查准率-召回率曲线展示了结果。在进行评估时,从测试数据中提取的关系将自动与Freebase中的关系进行比较。它是模型的近似度量,不需要昂贵的人工评估。
实验设置
在训练过程中,我们首先通过无监督深度聚类为含噪句子生成新的关系标签,然后对整个模型进行训练。在进行聚类时,我们使用k-means初始化聚类中心以加快收敛速度。采用过采样和欠采样策略来突出正样本的重要性,缓解数据不平衡问题。对于每个正样本,我们得到多个聚类结果,并通过投票确定其最终类别。此外,我们忽略了出现不到2次的6个长尾关系。$^1$
对于所有基线,在训练期间,我们遵循他们论文中使用的设置。表2显示了DCRE中使用的主要参数。
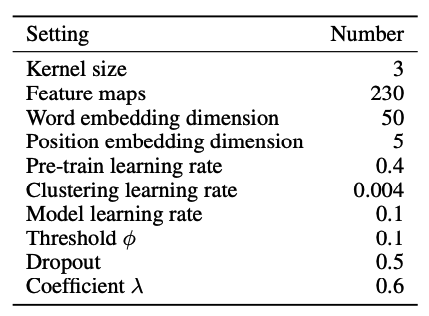
表2:参数设置
$^1$ 被忽略的关系:
/business/shopping_center_owner/shopping_centers_owned,
/location/fr_region/capital,
/location/mx_state/capital,
/business/shopping_center/owner,
/location/country/languages_spoken,
/base/locations/countries/states_provinces_within.
实验结果
基线
本文提出的模型在训练阶段直接处理有噪声的句子,因此我们选择了七个相关的工作作为基线。其中,PCNN+ATT、PCNN+WN、PCNN+C2SA和PCNN+ATT_RA+BAG_ATT是软决策方法,PCNN、PCNN+ATT+RL1和PCNN+ATT+RL2是硬决策方法。
- PCNN+ATT:Lin等人 (2016) 提出了一种基于PCNN句子编码器的对句子的选择性注意。
- PCNN+WN:Yuan等人(2019a)提出了一种非依赖的、同分布的关联性来捕获包中句子的关联性。
3.PCNN+C2SA:Yuan等人(2019b)提出交叉关系交叉包选择性注意力机制来处理噪声句子。 - PCNN+ATT_RA+BAG_ATT:Ye和Ling(2019)提出了包内和包间注意力机制,以在句子和包级处理噪声句子。这是最先进的方法。
- PCNN:Zeng等人(2015)提出了一种从句子包中选择标记最好的句子,而忽略其他句子的方法。
6.PCNN+ATT+RL1:Feng等人(2018)提出了一种强化方法,以去除句子包中的噪声句子。
7.PCNN+ATT+RL2:Qin, Xu, 和Wang(2018)也提出了强化模型。与(Feng等人(2018))不同,它将噪声句子重新分配为否定的例子。
我们实现了PCNN+ATT、PCNN+WN、PCNN和我们的DCRE。为了公平起见,我们使用作者提供的代码评估PCNN+C2SA$^2$、PCNN+ATT_RA+BAG_ATT$^3$、PCNN+ATT+RL2$^4$,并将其训练数据替换为具有522611个训练句子的训练数据。对于PCNN+ATT+RL1,我们使用Open-NRE$^5$提供的源代码。
$^2$https://github.com/yuanyu255/PCNN_C2SA
$^3$https://github.com/ZhixiuYe/Intra-Bag-and-Inter-Bag-Attentions
$^4$https://github.com/Panda0406/Reinforcement-Learning-Distant-Supervision-RE
$^5$https://github.com/thunlp/OpenNRE
DCRE的总体性能
图3显示了DCRE相对于七个基线的总体性能。左图显示了与软决策方法的比较结果。右图显示了硬决策方法的1.0比较结果。我们可以发现,我们的DCRE取得了所有0.9基线中最好的性能。
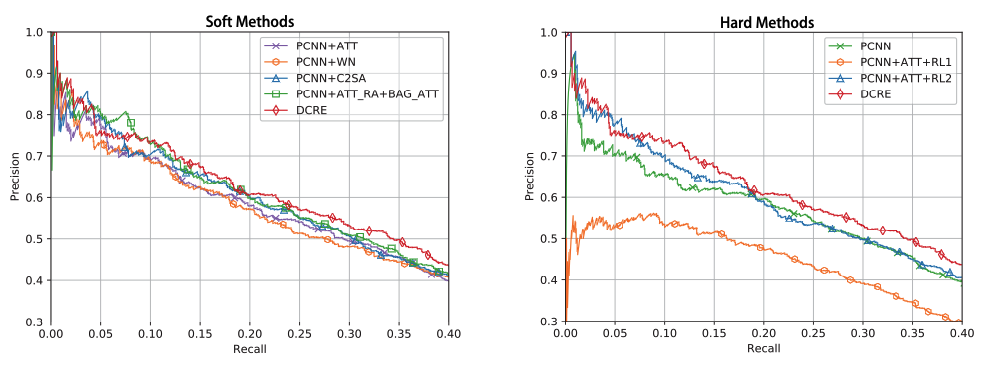
图3:与软方法(左)和硬方法(右)的比较结果。
将DCRE与四种软决策方法进行比较,如图3左半部分所示,我们有以下观察结果:(1)DCRE的性能远远优于PCNN+ATT和PCNN+WN。这说明对含噪句子赋予低权重只能减少其负面影响,但不能消除含噪句子的影响。(2) DCRE的性能略优于PCNN+AT_RA+BAG_ATT和PCNN+C2SA。与PCNN+ATT、PCNN+WN和DCRE不同,这两种方法根据超级包(Yuan 等人 2019b)获得最终表示,因此它们利用了更广泛的信息。而DCRE仍然比他们好。这表明我们为噪声句子找到高置信度标签的工作动机是有效的。
图3右侧显示了将DCRE与三种硬决策模型进行比较的结果。理想情况下,通过强化学习训练的实例选择器可以去除所有噪声句子,硬决策方法的性能应优于软决策方法。然而,可以观察到,DCRE与其他方法之间存在明显的差距。我们认为这主要是因为:(1)作为留出法评价的原则,测试数据中也存在噪声句。因此,很难将评估结果作为奖励来训练实例选择器。(2) 删除噪声句子确实可以消除它们的影响,但会忽略噪声句子中包含的有用信息。这一结果进一步验证了我们重新标记噪声句子并将其转换为有用的训练数据的直觉。
阈值影响
DCRE最重要的超参数是阈值$\phi$。为了分析$\phi$如何影响性能,我们通过在集合${0.15,0.1,0.05,0}$中选择$\phi$来进行实验,不同阈值的结果如图4所示。可以发现,$\phi$的设置是一个调和矛盾的过程,当$\phi=0.1$时,模型表现最好。这种现象背后的原因是:(1)大$\phi$意味着一些得分相对较高但无效的样本将被视为噪声句子。换句话说,这些句子的原始关系标签和新的关系标签都可能是错误的。(2) $\phi$相对较小表示过滤后的句子更可能是噪声句子。而在这种情况下,召回率太低。(3)当$\phi=0$时,该模型等于PCNN,PCNN只使用得分最高的句子。
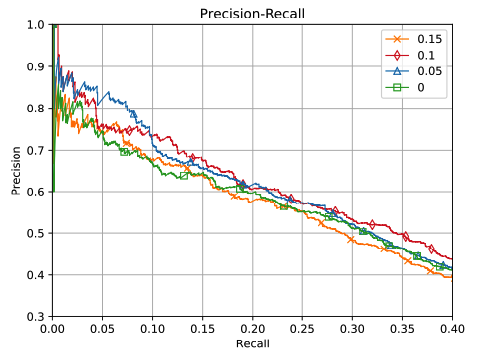
图4:阈值$\phi$的影响。
聚类结果
通过在训练过程中可视化聚类结果,进一步验证了深度聚类神经网络的有效性。我们将聚类数设置为47,不包括在训练数据中出现不到2次的6个长尾关系。我们不会删除更多的长尾关系,因为标记有其他关系的嘈杂句子可能会聚集到这些簇中。
我们随机选取1000个涵盖47个类别的句子,用t−SNE(Maaten和Hinton 2008)进行可视化,如图5所示。可以发现,在epoch 1中,不同的聚类之间有一个清晰的边界,但该聚类结果不能用于重新标记有噪声的句子。因为同一簇的点之间的距离太大,所以新标签的可信度相对较低。从可视化可以看出,从左到右,每个簇的“形状”越来越紧凑,簇之间的距离越来越远。因此,新标签的可信度越来越高。
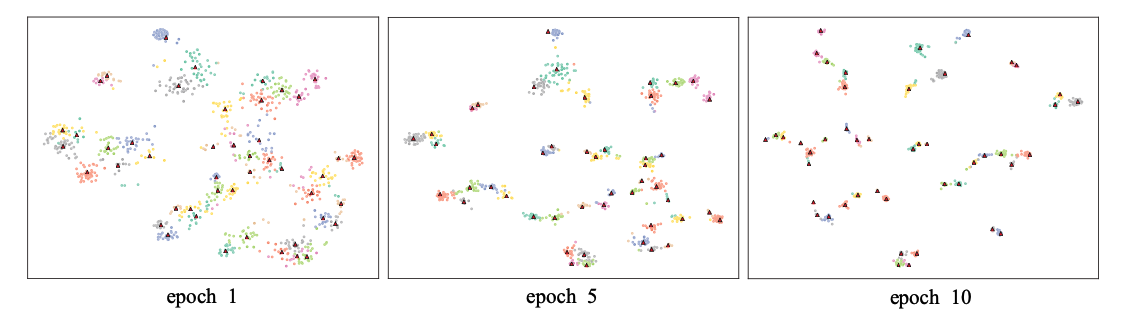
图5:对于NYT-10子集聚类结果的t-SNE可视化。红色三角形是簇中心。
在epoch 10,可以发现不同簇的某些点彼此接近。这种现象与现实是一致的,即一个句子可以表达多个关系。例如,$[Barack\ Obama]{e_1}$是$[United\ States]{e_2}$的第44任总统。是关系“$president\ of$”的高质量句子,关系“$live\ in$”的低质量句子。理想情况下,句子应该分为两类。在本文中,对于每个噪声句子我们只考虑一个高置信关系标签。
此外,我们在训练过程中随机选择了五个重新标注的句子,它们的新关系标签不同于原始标签,以显示噪声检测器和标签生成器的能力。它们的目标实体对、原始标签和生成的标签如表3所示。可以发现:(1)这五个句子的原始标签是错误的。这证明了阈值$\phi$的有效性。(2) 第1句的正确标签是$/location/country/capital$。最初的标签是错误的,因为远程监督无法确定该实体$[Beijing]$代表中国政府。生成的标签错误,主要是因为“$Beijing$”一词。(3) 确切地说,第四句的正确用法是“$people/person/place\_lived$”。其原始标签为$/people/person/nationality$,生成的标签为$/people/person/place\_of\_birth$。这三种关系有内在联系,因此模型很难找到正确的关系。
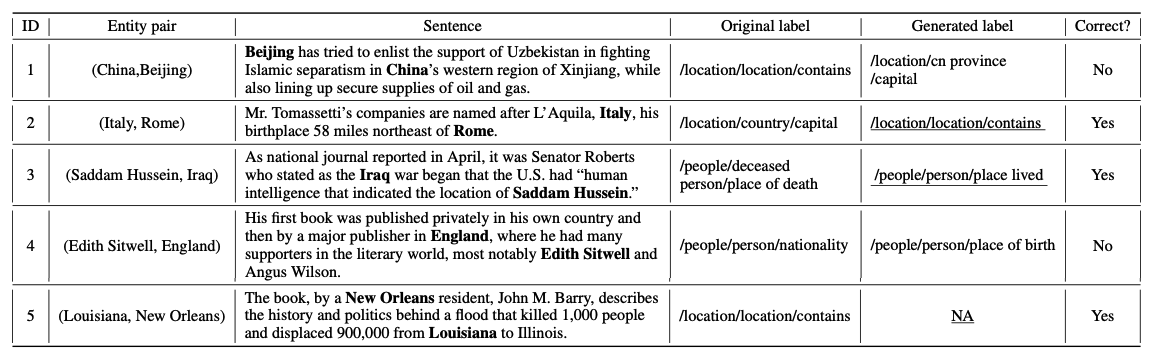
表3:在NYT-10数据集中随机选择五个句子。粗体文本表示实体,下划线文本表示关系标签是否正确。
结论和未来的工作
本文提出了一种基于无监督深度聚类的远程监督关系抽取模型。与传统的减少噪声句子影响的方法不同,我们的模型试图为噪声句子找到新的关系标签,并将其转换为有用的训练数据。大量的实验结果表明,该方法比同类方法具有更好的性能,并且确实可以缓解远距离监督关系抽取中的噪声标记问题。未来,我们将探索以下方向:
- 我们的聚类算法为每个噪声句子分配一个关系标签。而在现实中,一句话可以表达多种关系。我们将考虑在未来的多类聚类。
- 阈值$\phi$在DCRE中非常重要。接下来,我们将开发一种端到端的方法来自动选择嘈杂的句子,避免人工干预。
参考资料
[Bollacker et al. 2008] Bollacker, K.; Evans, C.; Paritosh, P.; Sturge, T.; and Taylor, J. 2008. Freebase: a collaboratively created graph database for structuring human knowledge. In Proceedings of the 2008 ACM SIGMOD international conference on Management of data, 1247–1250. AcM.
[Feng et al. 2018] Feng, J.; Huang, M.; Zhao, L.; Yang, Y.; and Zhu, X. 2018. Reinforcement learning for relation classification from noisy data. In Thirty-Second AAAI Conference on Artificial Intelligence.
[Ghasedi Dizaji et al. 2017] Ghasedi Dizaji, K.; Herandi, A.; Deng, C.; Cai, W.; and Huang, H. 2017. Deep clustering via joint convolutional autoencoder embedding and relative entropy minimization. In Proceedings of the IEEE International Conference on Computer Vision, 5736–5745.
[Guo et al. 2017a] Guo, X.; Gao, L.; Liu, X.; and Yin, J. 2017a. Improved deep embedded clustering with local structure preservation. In IJCAI, 1753–1759.
[Guo et al. 2017b] Guo, X.; Liu, X.; Zhu, E.; and Yin, J. 2017b. Deep clustering with convolutional autoencoders. In International Conference on Neural Information Processing, 373–382. Springer.
[Lin et al. 2016] Lin, Y.; Shen, S.; Liu, Z.; Luan, H.; and Sun, M. 2016. Neural relation extraction with selective attention over instances. In Proceedings of the 54th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), volume 1, 2124–2133.
[Maaten and Hinton 2008] Maaten, L. v. d., and Hinton, G. 2008. Visualizing data using t-sne. Journal of machine learning research 9(Nov):2579–2605.
[Mintz et al. 2009] Mintz, M.; Bills, S.; Snow, R.; and Jurafsky, D. 2009. Distant supervision for relation extraction without labeled data. In Proceedings of the Joint Conference of the 47th Annual Meeting of the ACL and the 4th International Joint Conference on Natural Language Processing of the AFNLP: Volume 2-Volume 2, 1003–1011. Association for Computational Linguistics.
[Qin, Xu, and Wang 2018] Qin, P.; Xu, W.; and Wang, W. Y. 2018. Robust distant supervision relation extraction via deep reinforcement learning. meeting of the association for computational linguistics 1:2137–2147.
[Riedel, Yao, and Mccallum 2010] Riedel, S.; Yao, L.; and Mccallum, A. 2010. Modeling relations and their mentions without labeled text. In European Conference on Machine Learning Knowledge Discovery in Databases.
[Shore and Johnson 1980] Shore, J., and Johnson, R. 1980. Axiomatic derivation of the principle of maximum entropy and the principle of minimum cross-entropy. IEEE Transactions on information theory 26(1):26–37.
[Srivastava et al. 2014] Srivastava, N.; Hinton, G.; Krizhevsky, A.; Sutskever, I.; and Salakhutdinov, R. 2014. Dropout: a simple way to prevent neural networks from overfitting. The journal of machine learning research 15(1):1929–1958.
[Takamatsu, Sato, and Nakagawa 2012] Takamatsu, S.; Sato, I.; and Nakagawa, H. 2012. Reducing wrong labels in distant supervision for relation extraction. In Proceedings of the 50th Annual Meeting of the Association for Computational Linguistics: Long Papers-Volume 1, 721–729. Association for Computational Linguistics.
[Tian et al. 2014] Tian, F.; Gao, B.; Cui, Q.; Chen, E.; and Liu, T.-Y. 2014. Learning deep representations for graph clustering. In Twenty-Eighth AAAI Conference on Artificial Intelligence.
[Wang et al. 2018] Wang, G.; Zhang, W.; Wang, R.; Zhou, Y.; Chen, X.; Zhang, W.; Zhu, H.; and Chen, H. 2018. Labelfree distant supervision for relation extraction via knowledge graph embedding. In Proceedings of the 2018 Conference on Empirical Methods in Natural Language Processing, 2246–2255.
[Wu, Fan, and Zhang 2019] Wu, S.; Fan, K.; and Zhang, Q. 2019. Improving distantly supervised relation extraction with neural noise converter and conditional optimal selector. In Proceedings of the AAAI Conference on Artificial Intelligence, volume 33, 7273–7280.
[Xie, Girshick, and Farhadi 2016] Xie, J.; Girshick, R.; and Farhadi, A. 2016. Unsupervised deep embedding for clustering analysis. In International conference on machine learning, 478–487.
[Ye and Ling 2019] Ye, Z.-X., and Ling, Z.-H. 2019. Distant supervision relation extraction with intra-bag and inter-bag attentions. In Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long and Short Papers), 2810–2819. Minneapolis, Minnesota: Association for Computational Linguistics.
[Yuan et al. 2019a] Yuan, C.; Huang, H.; Feng, C.; Liu, X.; and Wei, X. 2019a. Distant supervision for relation extraction with linear attenuation simulation and non-iid relevance embedding. In Proceedings of the AAAI Conference on Artificial Intelligence, volume 33, 7418–7425.
[Yuan et al. 2019b] Yuan, Y.; Liu, L.; Tang, S.; Zhang, Z.; Zhuang, Y.; Pu, S.; Wu, F.; and Ren, X. 2019b. Crossrelation cross-bag attention for distantly-supervised relation extraction. In Proceedings of the AAAI Conference on Artificial Intelligence, volume 33, 419–426.
[Zeng et al. 2014] Zeng, D.; Liu, K.; Lai, S.; Zhou, G.; and Zhao, J. 2014. Relation classification via convolutional deep neural network. In Proceedings of COLING 2014, the 25th International Conference on Computational Linguistics: Technical Papers, 2335–2344.
[Zeng et al. 2015] Zeng, D.; Liu, K.; Chen, Y.; and Zhao, J. 2015. Distant supervision for relation extraction via piece-wise convolutional neural networks. In Proceedings of the 2015 Conference on Empirical Methods in Natural Language Processing, 1753–1762.

