$Wei\ Jia, Dai\ Dai, Xinyan\ Xiao\ and\ Hua\ Wu$
$百度, 北京, 中国$
${jiawei07, daidai, xiaoxinyan, wu hua} @baidu.com$
摘要
远程监督广泛应用于关系分类中,通过将知识库与未标记的语料库对齐来创建大规模的训练数据。然而,它也引入了大量噪声标签,而上下文句子实际上并不表示标签关系。在本文中,我们提出了ARNOR,一种新的基于注意力正则化的降噪框架(Attention Regularization based NOise Reduction),用于远程监督关系分类。ARNOR假设一个可信的关系标签应该用神经注意力模型来解释。具体地说,我们的ARNOR框架迭代地学习可解释的模型,并利用它来选择可信任的实例。我们首先引入注意力正则化,迫使模型注意解释关系标签的模式,从而使模型更具解释性。然后,如果学习到的模型能够清楚地定位训练集中候选实例的关系模式,我们将选择它作为可信任实例进行进一步训练。根据对NYT数据的实验,我们的ARNOR框架在关系分类性能和降噪效果方面都比现有的方法有了显著的改进。
1 概述
关系分类(RC)是自然语言处理(NLP)中的一项基本任务,对知识库的构建尤为重要。RC(Zelenko 等人,2003)的目标是识别句子中给定实体对的关系类型。一般来说,一个关系应该用一些线索词来表达。请参见图1中的第一句话。短语“was born in”解释了“Bill Lockyer”和“California”的关系类型“place of birth”。这种指示词被称为模式(earst, 1992; Hamon 和 Nazarenko, 2001)。

图1: 由远程监控生成的两个关系实例。$s_1$中粗体字“was born in”是解释关系类型“place of birth”的模式。因此,此实例已正确标记。然而,第二个实例由于缺乏相应的关系模式而存在噪声。
为了廉价获得大量标记的RC训练数据,远程监督(DS)(Mintz 等人,2009)提出通过将知识库与未标记的语料库对齐来自动生成训练数据。它建立在一个较弱的假设之上,即如果一个实体对在一个知识库中有一个关系,那么包含该对的所有句子都将表达相应的关系。
不幸的是,DS显然带来了大量的噪声数据,这可能会显著降低RC模型的性能。可能没有明确的关系模式来标识关系。例如,参见图1中的第二句话。Mintz 等人,2009报告说,远程监控可能会导致30%以上的噪音。另一方面,基于这些噪声数据,基于注意的神经模型通常只关注实体词,而不关注模式(见图2)。
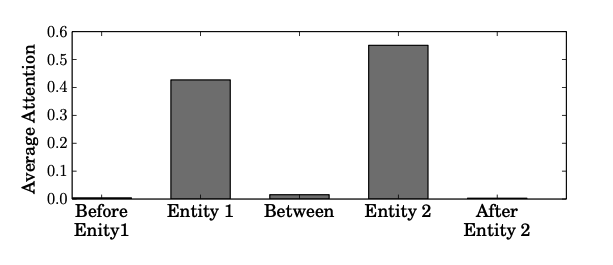
图2: 在我们的测试集中,五部分句子中BiLSTM+ATT模型的平均注意力权重。该模型使用远程监督构造的噪声数据进行训练。它主要关注输入实体对,而忽略其他可能表达真实关系的词。它也发生在图1中。这个结果来自这样一个事实,即DS方法只依赖于实体来标记数据。
处理此类噪声问题的方法主要有三种。首先,多实例学习(Riedel 等人,2010;Lin 等人,2016;Surdeanu 等人,2012;Zeng 等人,2015)将DS假设放松为至少一个。在一组提到同一实体对的句子中,它假设至少有一个句子表达了这种关系。多实例学习在包级上进行分类,在句子级预测上往往表现不佳(Feng等人,2018b)。其次,为了减少句子级预测的噪音,研究人员随后采用强化学习或对抗性训练来选择可信的数据(Feng 等人, 2018b; Qin 等人, 2018a; Han 等人, 2018; Xiangrong 等人, 2018; Qin 等人, 2018b)。这一研究路线通过将模型学习后的预测标签与DS生成的标签相匹配来选择可靠的关系标签。由于模型也是从DS数据中学习的,因此当模型预测和DS生成的标签都错误时,它仍可能失败。第三种方法依赖于关系模式。基于模式的提取广泛应用于信息提取(Hearst, 1992; Hamon 和 Nazarenko, 2001)。其中,生成模型(Takamatsu 等人,2012)直接模拟DS的标记过程,并发现错误标记关系的噪声模式。数据编程(Ratner等人,2016年、2017年)融合了基于DS的标签和手动关系模式,以降低噪音。
在本文中,我们提出了ARNOR,一种新的基于注意力正则化的降噪框架。ARNOR的目标是训练一个神经模型,该模型能够通过注意力正则化(AR)清晰地解释关系模式,同时根据一个假设减少噪音:模型在一个实例中解释关系越清晰,这种立场就越可信。具体来说,我们的ARNOR框架迭代学习可解释模型并选择可信任实例。我们首先在神经模型上使用注意正则化来关注关系模式(第3.4节将介绍模式构造)。然后,如果学习到的模型能够发现候选实例的模式,我们将选择这些候选实例作为正确的标记数据,用于进一步的训练步骤。这两个步骤是相互加强的。模型解释性越强,选择的训练数据越好,反之亦然。
此外,大多数以前基于DS的RC模型都是在测试集上进行近似评估的,测试集从训练集中分离出来,因此也充满了噪声数据。我们认为这可能不是最好的选择。相反,我们使用最近发布的句子级测试集(Ren等人,2017)进行评估。然而,该测试集也存在一些问题(见第4.1节)。我们提出了一个更大更精确的修订版本。
总的来说,贡献如下:
我们提出了一种新的注意正则化方法来降低DS中的噪声。我们的方法迫使模型从注意的角度清楚地解释关系模式,如果模型能够解释,则选择可信任的实例。
我们的ARNOR框架在RC性能和降噪效果方面都比最先进的降噪方法有了显著的改进。
我们发布了一个更好的手动标记句子级测试集$^1$,用于评估RC模型的性能。该测试集包含1024个句子和4543个实体对,并仔细注释以确保准确性。
$^1$ 本文使用的数据集位于 https://github.com/PaddlePaddle/models/tree/develop/PaddleNLP/ Research/ACL2019-ARNOR
2 相关工作
本文主要研究基于DS的RC。对于RC任务,最近提出了基于不同神经结构的各种模型,例如卷积神经网络(Zeng等人,2014年,2015年)和递归神经网络(Zhang等人,2015年;Zhou等人,2016年)。为了自动获得大型训练数据集,提出了DS(Mintz等人,2009)。然而,DS也引入了噪声数据,使得基于DS的RC更具挑战性。
以往的研究尝试了各种方法来解决噪声问题。第一种广泛研究的方法基于多实例学习(Riedel等人,2010年;Lin等人,2016年;Surdeanu等人,2012年;Zeng等人,2015年)。然而,它在一包实例上建模噪声问题,不适合句子级预测。第二种方法利用RL(Feng等人,2018b;Xianglong等人,2018;Qin等人,2018b)或对抗训练(Qin等人,2018a;Han等人,2018)来选择可信任的实例。第三条研究路线依赖于模式(赫斯特,1992年;哈蒙和纳扎连科,2001年)。Takamatsu等人(2012年)直接对DS的标记过程进行建模,以发现噪声模式。Ratner等人(2016年、2017年)建议融合基于DS的标签和手动关系模式,以降低噪音。Feng等人(2018a)提出了一种基于RL的模式提取器,并使用提取的模式作为RC的特征。
3 ARNOR 框架
在本文中,我们通过观察到一个关系应该用它的句子上下文来表达,从而减少了DS噪声并使模型更易于解释。一般来说,RC分类器应该依赖关系模式来决定一对实体的关系类型。因此,对于训练实例,如果这样的可解释模型不能关注到表示关系类型的模式,则该实例可能是噪声。
我们的ARNOR框架由两部分组成:注意正则化训练和实例选择。首先,我们希望该模型能够定位关系模式。因此,注意正则化被用于指导模型的训练,迫使它注意给定的模式词。然后,我们通过检查模型是否能够清楚地解释DS生成的关系标签来选择实例。在bootstrap过程中重复这两个步骤。我们在图3中说明了我们的方法。
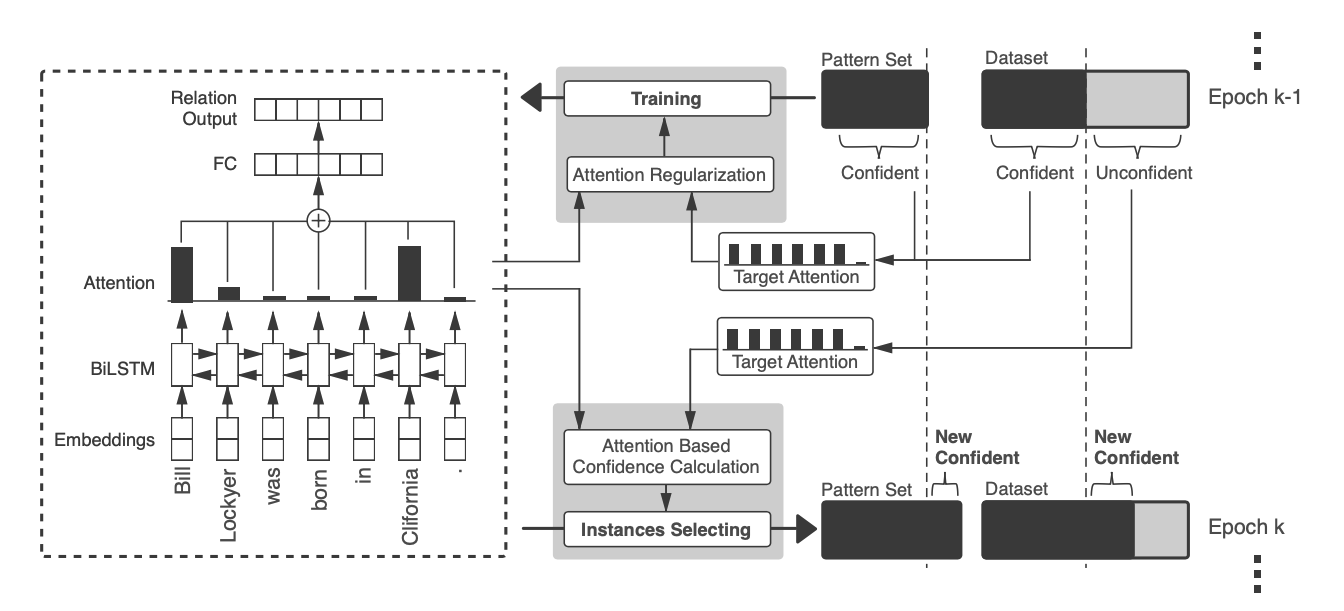
图3: 我们的ARNOR框架概述。它基于具有注意机制的BiLSTM,并利用注意正则化强制模型关注相应的关系模式。然后,实例选择器计算每个训练实例的置信度分数,以生成新的重新分配的训练集和新的可信任模式集。这两个步骤迭代运行,形成一个bootstrap学习过程。
3.1 基于注意力的BiLSTM编码器
为了捕获用于识别关系的关键特征词,我们在BiLSTM编码器上应用了注意机制,该机制首次在(Zhou等人,2016)中针对RC引入。模型架构如图3左侧所示。
输入嵌入
输入嵌入包括三个部分:单词嵌入、位置嵌入和实体类型嵌入。位置嵌入最早由Zeng等人(2014)提出,以纳入输入实体对的位置信息,并已广泛应用于之后的RC模型中。我们还通过查找实体类型嵌入矩阵来引入实体类型信息。最终的输入嵌入是这些嵌入的串联,并通过注意机制反馈给双向长短期记忆(BiLSTM)以生成句子表示。
基于注意力的BiLSTM
设$H={h_i}$表示BiLSTM编码器的隐藏向量。最后的句子表示$u$是这些向量的加权和,
$$M=tanh(H)\a=softmax(w^TM)\u=Ha^T$$
其中$w^T$是经过训练的参数向量。研究表明,注意机制有助于获取分类任务的重要特征。然而,对于远程监督产生的噪声数据,它几乎只关注实体,而忽略了对RC更具信息量的关系模式。
3.2 使用注意力正则化训练
注意正则化(AR)旨在指导模型关注关系模式以识别关系。给定一个$T$个字的句子$s={x_i}^T_{i=1}$,$s$中的一对实体$(e_1,e_2)$,一个关系标签$y$,以及一个表示$e_1$和$e_2$关系$y$的关系模式$m$。(第3.4节将介绍关系模式$m$的构造)。我们能够根据模式提及重要性函数$q(z|s,e_1,e_2,m)$在输入$m$下计算注意引导值$a^m$。这里$z$表示句子中的模式词。我们希望分类器能够将其注意力分布$a^s=p(z | s)$近似为$a^m$,其中$p$表示分类器网络。直观地说,我们采用KL(Kullback–Leibler diver-gence)作为优化函数,该函数描述了分布之间的差异:
$$KL(a^m|a^s)=\sum a^m \log \frac{a^m}{a^s}$$
此外,等式2可进一步简化为:
$$loss_a=\sum a^m \log \frac{a^m}{a^s} =\sum (a^m \log a^m - a^m \log a^s)$$
其中$loss_a$代表注意力正则的损失。由于$a^m$为常量,因此方程式等于
$$loss_a=- \sum a^m \log a^s$$
因此,我们将$loss_a$应用到分类损失$loss_c$中,以规范注意学习。最后的损失是
$$loss=loss_c+\beta loss_a$$
其中$\beta$是$loss_a$的权重,在我们的实验中通常设置为1。
在本文中,我们实现了一个相当简单的函数来生成$a^m$。
$$
b_i=\begin{cases}
1, & x_i\in {e_i,e_2,m} \
0, & else
\end{cases}
\a^m \left { \frac{b_k}{\sum^T_{i=1}b_i} \right }^T_{k=1}
$$
这里$b$表示$x_i$是否属于实体词和关系模式词。
3.3 基于模型注意力的实例选择
基于注意力机制,经过训练的RC模型可以告诉我们每个单词对于识别关系类型的重要性。对于训练实例,如果模型关注的关系模式词与解释关系类型的模式$m$不匹配,则该实例可能为假阳性。在这里,我们仍然应用KL来度量实例为假阳性的概率。考虑到RC模型中的注意力权重$a^s$和由等式6计算的$a^m$,实例的置信度得分$c$规范化于
$$c=\frac{1}{1+KL(a^m||a^s)}$$
$c$值越高,实例越可信。我们计算训练集中所有实例的置信度得分,并选择得分大于阈值$c_t$(一个超参数)的实例。
3.4 bootstrap学习过程
在我们的ARNOR框架中,一个重要的问题是如何在模型训练和实例选择步骤中获取关系模式$m$。在模型训练步骤中,我们需要更精确的模式来引导模型关注RC的重要证据。而在实例选择步骤中,需要更多不同的模式,以选择更可靠的数据,并发现更可靠的关系模式。这里我们将简单地定义bootstrap学习步骤的过程。在模型训练中,给定1)一个模式提取器$E$,它可以从一个实例中提取一个关系模式,2)一个初始的可信任模式集$M$(可以手动收集或使用$E$简单地从原始训练数据集$D$中计数)。首先,我们基于$M$(如下所述)重新分配训练数据集$D$。然后,仅使用$M$中的$m$对RC模型进行一定epoch的训练。接下来,在$D$上运行实例选择以选择更可靠的训练数据。这些新的可信任实例被提供给$E$,以找出新的可信任模式并将它们放入$M$。我们重复这样的bootstrap过程,直到开发集上的F1分数不增加为止。该bootstrap过程在算法1中有详细说明。

关系模式抽取
另一个问题是如何构建关系模式提取器$E$以从实例中提取模式。然而,我们发现这并不十分关键。即使我们使用一种非常简单的方法,我们仍然取得了相当大的进步。可以肯定的是,一个更复杂、性能更好的提取器将带来额外的改进。这将是我们今后的工作之一。我们的模式提取器$E$只是将两个实体之间的单词作为关系模式。对于初始模式集$M$的构建,我们从原始训练数据集中的所有实例中提取关系模式,并对它们进行计数。$M$最初是通过选择具有引用的模式来构建的。我们为每种关系类型保留前10%(最多20)的模式。
数据分布
在构建可信任模式集$M$之后,数据集$D$将使用这些模式重新分布。所有与这些模式不匹配的正实例将被放入负集合,将它们的关系标签修改为“None”。我们将在实验部分解释数据重新分布的原因。
4 实验
4.1 数据集和评估
我们在广泛使用的公共数据集:NYT上评估了提议的ARNOR框架,NYT是从1989-2007年《纽约时报》的294k新闻文章中抽取的一个新闻语料库,首次出现在(Riedel等人,2010年)。大多数以前的工作通常通过对齐Freebase中的实体对来生成训练实例,并采用留出法评估来评估,而无需昂贵的人工注释。由于远程监督也会产生噪声测试集,因此此类评估只能提供近似测量值。相比之下,Ren等人(2017年)发布了一个也由远程监督生成的训练集,但这是一个手动注释的测试集,包含Hoffmann等人(2011年)的395个句子。然而,我们发现这个测试集只为一个句子标注了一个实体对。这些句子中并非所有的三元组都被标注出来了。此外,尽管有足够的测试实例(3880个,包括“None”类型),但正样例的数量相对较少(只有396个)。此外,测试集只包含训练集关系类型的一半。
为了解决这些问题并更准确地评估我们的ARNOR框架,我们在Ren等人(2017)发布的测试集的基础上注释并发布了一个新的句子级测试集(源地址见第1节),该测试集还包含注释命名实体类型。首先,我们对原395个测试句中错误标注的实例进行了修正。然后,从原始训练集中抽取约600个句子。我们仔细检查它们的标签,并将它们合并到测试集中。我们还移除了一些重叠和不明确的关系类型,或者噪声太大而无法获得非噪声测试样本的关系类型。该数据集的详细信息以及我们使用的关系类型如表1和表2所示。
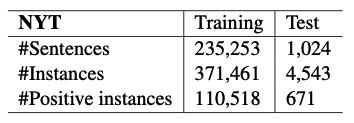
表1: 实验中数据集的统计。
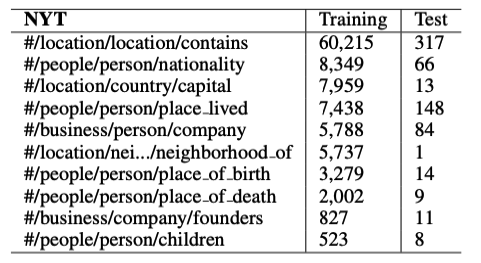
表2: 我们保留的10种关系类型及其在数据集中的统计信息。某些关系类型在测试集中的分布是不同的,因为它们的噪声要大得多。
对于评估,我们在句子级别(或实例级别)评估我们的框架。句子级预测更适合于理解句子任务,如问答和语义分析(Feng等人,2018b)。与常用的包级别评估不同,句子级别评估直接对数据集中的所有实例计算精度(Prec.)、召回率(Rec.)和F1度量。我们认为这样的评估更直观,更适合于实际应用。
4.2 基线模型
我们将我们的ARNOR框架与几个用于降噪的强基线进行比较,如下所示:
PCNN+SelATT(Lin等人,2016)是一种包级RC模型。它对包中的所有句子都采用注意机制,因此可以减少噪声数据的权重。
CNN+RL2(Feng等人,2018b)是一种新的基于强化学习(RL)的模型,用于从噪声数据中提取RC。它联合训练一个用于RC的CNN模型以及一个实例选择器,以移除不一致的样本。
CNN+RL1(Qin等人,2018b)也引入了RL来启发式地识别假阳性实例。与Feng等人(2018b)不同,他们将假阳性重新分配到阴性样本中,而不是将其移除。
同时,为了验证去噪后的RC算法的有效性,还对几种非去噪方法进行了比较。
CNN(Zeng等人,2014)是一种广泛使用的RE架构。它引入位置嵌入来表示输入实体对的位置。
PCNN(Zeng等人,2015)是CNN的修订版,它使用分段最大池来提取更多的关系特征。
BiLSTM(Zhang等人,2015)也常用于借助位置嵌入的RE。BiLSTM+ATT(Zhou等人,2016)在BiLSTM中添加了一种注意机制,以捕捉识别关系的最重要特征。它是我们ARNOR框架中使用的基本模型。
4.3 实现细节
对于我们的模型和其他基于BiLSTM的基线,单词嵌入随机初始化为100维。位置嵌入和实体类型嵌入随机初始化为50个维度。BiLSTM隐层向量的大小设置为500。在注意正则化训练中,参数$\beta$设置为1。我们将学习率设置为0.001,并利用Adam进行优化。为了更好地评估我们的模型,我们将测试数据集平均分为开发集和测试集。在实例选择步骤中,将适当的置信度得分阈值设置为0.5,这在其他数据集中应该是不同的。对于每种关系类型,我们在一个循环中最多使用5种新模式。在bootstrap过程中,我们在第一个循环中运行10个epoch,在其余循环中运行1个epoch,直到开发集上的分类性能没有增加。通常,bootstrap过程以5个循环结束。对于基于CNN的基线,我们使用相同的嵌入设置。卷积层的窗口大小设置为3,滤波器的数目设置为230。所有降噪基线均使用其作者发布的源代码实现。
4.4 主要结果
我们比较了ARNOR与非去噪基线和去噪基线的结果。如表3所示,ARNOR在精度和F1指标方面均显著优于所有基线,与最先进的CNN+RL2相比,F1提高了约11%。注意,我们的模型在查准率上取得了巨大的提高,而查全率没有太大的下降。这表明所提出的框架可以有效地减少噪声数据的影响。在所有基线中,PCNN+SelATT的性能最差。我们认为这是因为PCNN+SelATT是一种包级方法,不适合句子级评估,这与Feng等人(2018b)的观点一致。
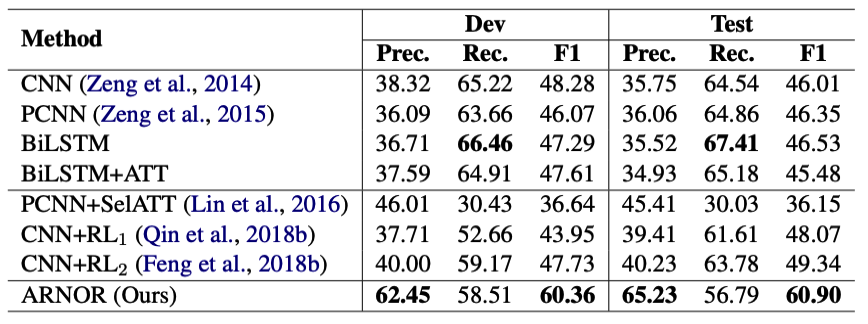
表3: 我们的方法与其他基线的比较。前三种方法是常规RC模型,中间三条基线是远程监督RC模型。
5 分析和讨论
5.1 组建功效
为了找出哪个组件对我们的框架有贡献,我们通过添加每个组件来评估我们的模型。结果如表4所示。BiLSTM+ATT是由原始噪声数据训练的基线模型。在使用通过上述部分所述方法生成的初始重新分配的数据集后,BiLSTM+ATT模型在F1中实现了约6%的改进。并且精度大幅提高约26%。这表明DS数据集包含大量噪声。即使是这样一种简单的噪声滤波方法也可以有效地提高模型性能。然而,这种简单的方法严重影响了召回率。一方面,带有长尾模式的真阳性数量将被错误地视为假阴性。我们猜测训练数据中的一些关系模式太少,以至于模型无法学习它们。因此,在我们将注意力正则化添加到模型中后,召回率增加了约10%,而准确率仅下降了2%。因此,我们的模型实现了另外7%的F1改进。我们认为,这是引导模型理解哪些词对确定关系更为重要的力量。在我们获得一个经过注意正则化训练的初始模型后,我们继续bootstrap学习过程,最终获得2.4%的F1改进。在此过程中,ARNOR将收集更可靠的长尾模式,以提高模型的召回率。
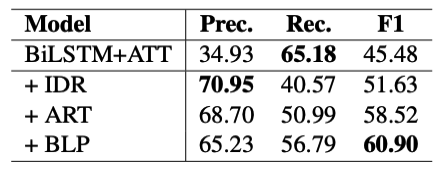
表4: 评估我们框架中的组件。BiLSTM+ATT是不降低噪声的基础模型。IDR代表使用初始模式集重新分配初始数据。ART表示第一个循环的注意力规则化训练。BLP代表bootstrap学习过程。
5.2 从干净的小数据或嘈杂的大数据开始
在上一节中,我们发现初始重新分布的数据集(具有小而干净的正数据)有助于模型的改进。与此相反,以往基于神经网络的远程监控RC模型,包括本文中的所有基线,通常是从原始数据集开始的,该数据集很大,但有噪声。哪个是更好的选择?为了解决这个问题,我们使用相同的初始重新分布数据集对CNN+RL2中使用的CNN进行预训练,然后对原始噪声数据集应用RL2过程进行降噪。我们在表5中报告了结果。预训练的PCNN也取得了显著的改善,经过RL2进一步去噪后,CNN+RL2最终在F1中获得了57.89%,仍然比我们模型的性能低3%。因此,我们认为,以较小但干净的数据集启动模型可能是降低噪声的一种选择。
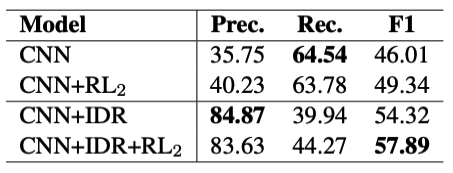
表5: CNN+RL2的结果(Feng等人,2018b)从使用初始数据重新分布(IDR)的预训练CNN模型开始。CNN+IDR是根据最初重新分配的数据训练的模型,CNN+IDR+RL2将RL2应用于预先训练的CNN+IDR模型。
5.3 降噪效果
ARNOR框架中的实例选择器通过检查注意权重是否与给定模式匹配来计算训练集中每个实例的置信度分数。然后我们利用这个置信度得分来减少噪声。为了验证降噪能力,我们随机抽取200个句子来标注它们是否是噪声,并用它们来评估降噪的准确性。我们将结果与表6中的CNN+RL2进行比较。ARNOR在准确率上明显优于CNN+RL2,并获得14.92%的F1改进。
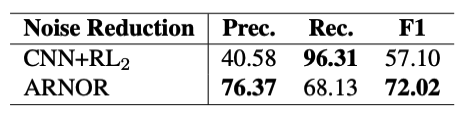
表6: 降噪效果比较。我们从训练集中随机抽取200个句子(529个句子)。经人工检查,其中213处无噪声。我们使用这些样本来评估降低噪声的能力。
5.4 案例研究
我们的ARNOR能够通过注意正则化训练使RC模型更易于解释。为了验证这一点,我们从测试集中选择了一些实例,并将它们的注意力权重可视化,以便进行案例研究。如表7所示,在原始噪声数据上训练的BiLSTM+ATT只关注实体对,并且在这些情况下做出错误的预测。这可能是因为模型没有学习到RC的关键证据。而ARNOR能够完美地捕捉重要特征并正确预测关系。

表7: 这是一个有热图的注意案例。这些案例显示了我们的模型定位关系指标的能力。基于注意监督,我们的模型可以专注于关系模式和实体。
此外,我们还检查了在bootstrap学习中发现的自信模式。如表8所示,通过初步建立自信模式集,可以很容易地获得高频模式,并且在bootstrap学习后,我们可以发现更多的长尾模式,其中大多数是有代表性和有意义的。更重要的是,这些附加模式中的一些在字面上并不相似,这表明该模型可以学习相关特征词之间的语义关联。

表8: 模式集案例。此表显示了我们的模型在模式bootstrap中发现的一些高频和顶部长尾模式。
6 结论
我们提出了ARNOR,一个基于注意力正则化的噪声抑制框架,用于远程监控关系分类。我们发现,关系模式是一个重要的特征,但以前的模型在噪声数据上训练时很少捕捉到。因此,我们设计了注意规则来帮助模型学习关系模式的定位。使用更具解释性的模型,我们然后通过评估模型对实例关系的解释程度来进行降噪。建立了一个bootstrap学习过程,迭代地改进模型、训练数据和可信模式集。通过一个非常简单的模式提取器,我们的性能超过了几个基于RL的强基线,在关系分类和噪声降低方面都取得了显著的改进。此外,我们还发布了一个更好的手动标记测试集,用于句子级评估。
在未来,我们希望通过使用更好的基于模型的模式提取器,并采用潜变量模型(Kim等人,2018)来联合建模实例选择器,从而改进我们的工作。此外,我们还希望验证我们的方法在更多任务上的有效性,包括开放信息提取和事件提取,以及重叠关系提取模型(Dai等人,2019年)。
参考文献
Dai Dai, Xinyan Xiao, Yajuan Lyu, Qiaoqiao She, Shan Dou, and Haifeng Wang. 2019. Joint extraction of entities and overlapping relations using positionattentive sequence labeling. In Thirty-Third AAAI Conference on Artificial Intelligence (AAAI 2019), Honolulu, USA, January 27, 2019.
Jun Feng, Minlie Huang, Yijie Zhang, Yang Yang, and Xiaoyan Zhu. 2018a. Relation mention extraction from noisy data with hierarchical reinforcement learning. arXiv preprint arXiv:1811.01237.
Jun Feng, Minlie Huang, Li Zhao, Yang Yang, and Xiaoyan Zhu. 2018b. Reinforcement learning for relation classification from noisy data. In Proceedings of AAAI.
Thierry Hamon and Adeline Nazarenko. 2001. Detection of synonymy links between terms: experiment and results. Recent advances in computational terminology, 2:185–208.
Xu Han, Zhiyuan Liu, and Maosong Sun. 2018. Denoising distant supervision for relation extraction via instance-level adversarial training. arXiv preprint arXiv:1805.10959.
Marti A. Hearst. 1992. Automatic acquisition of hyponyms from large text corpora. In COLING 1992 Volume 2: The 15th International Conference on Computational Linguistics.
Raphael Hoffmann, Congle Zhang, Xiao Ling, Luke Zettlemoyer, and Daniel S Weld. 2011. Knowledgebased weak supervision for information extraction of overlapping relations. In Proceedings of the 49th Annual Meeting of the Association for Computational Linguistics: Human Language TechnologiesVolume 1, pages 541–550. Association for Computational Linguistics.
Yoon Kim, Sam Wiseman, and Alexander M Rush. 2018. A tutorial on deep latent variable models of natural language. arXiv preprint arXiv:1812.06834.
Yankai Lin, Shiqi Shen, Zhiyuan Liu, Huanbo Luan, and Maosong Sun. 2016. Neural relation extraction with selective attention over instances. In Proceedings of the 54th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), volume 1, pages 2124–2133.
Mike Mintz, Steven Bills, Rion Snow, and Dan Jurafsky. 2009. Distant supervision for relation extraction without labeled data. In Proceedings of the Joint Conference of the 47th Annual Meeting of the ACL and the 4th International Joint Conference on Natural Language Processing of the AFNLP: Volume 2-Volume 2, pages 1003–1011. Association for Computational Linguistics.
Pengda Qin, Weiran Xu, and William Yang Wang. 2018a. Dsgan: Generative adversarial training for distant supervision relation extraction. arXiv preprint arXiv:1805.09929.
Pengda Qin, Weiran Xu, and William Yang Wang. 2018b. Robust distant supervision relation extraction via deep reinforcement learning. arXiv preprint arXiv:1805.09927.
Alexander Ratner, Stephen H Bach, Henry Ehrenberg, Jason Fries, Sen Wu, and Christopher Re ́. 2017. Snorkel: Rapid training data creation with weak supervision. Proceedings of the VLDB Endowment, 11(3):269–282.
Alexander J Ratner, Christopher M De Sa, Sen Wu, Daniel Selsam, and Christopher Re ́. 2016. Data programming: Creating large training sets, quickly. In Advances in neural information processing systems, pages 3567–3575.
Xiang Ren, Zeqiu Wu, Wenqi He, Meng Qu, Clare R Voss, Heng Ji, Tarek F Abdelzaher, and Jiawei Han. 2017. Cotype: Joint extraction of typed entities and relations with knowledge bases. In Proceedings of the 26th International Conference on World Wide Web, pages 1015–1024. International World Wide Web Conferences Steering Committee.
Sebastian Riedel, Limin Yao, and Andrew McCallum. 2010. Modeling relations and their mentions without labeled text. In Joint European Conference on Machine Learning and Knowledge Discovery in Databases, pages 148–163. Springer.
Mihai Surdeanu, Julie Tibshirani, Ramesh Nallapati, and Christopher D Manning. 2012. Multi-instance multi-label learning for relation extraction. In Proceedings of the 2012 joint conference on empirical methods in natural language processing and computational natural language learning, pages 455–465. Association for Computational Linguistics.
Shingo Takamatsu, Issei Sato, and Hiroshi Nakagawa. 2012. Reducing wrong labels in distant supervision for relation extraction. In Proceedings of the 50th Annual Meeting of the Association for Computational Linguistics: Long Papers-Volume 1, pages 721–729. Association for Computational Linguistics.
Zeng Xiangrong, Liu Kang, He Shizhu, Zhao Jun, et al. 2018. Large scaled relation extraction with reinforcement learning.
Dmitry Zelenko, Chinatsu Aone, and Anthony Richardella. 2003. Kernel methods for relation extraction. Journal of machine learning research, 3(Feb):1083–1106.
Daojian Zeng, Kang Liu, Yubo Chen, and Jun Zhao. 2015. Distant supervision for relation extraction via piecewise convolutional neural networks. In Proceedings of the 2015 Conference on Empirical Methods in Natural Language Processing, pages 1753– 1762.
Daojian Zeng, Kang Liu, Siwei Lai, Guangyou Zhou, and Jun Zhao. 2014. Relation classification via convolutional deep neural network. In Proceedings of COLING 2014, the 25th International Conference on Computational Linguistics: Technical Papers, pages 2335–2344.
Shu Zhang, Dequan Zheng, Xinchen Hu, and Ming Yang. 2015. Bidirectional long short-term memory networks for relation classification. In Proceedings of the 29th Pacific Asia Conference on Language, Information and Computation, pages 73–78.
Peng Zhou, Wei Shi, Jun Tian, Zhenyu Qi, Bingchen Li, Hongwei Hao, and Bo Xu. 2016. Attentionbased bidirectional long short-term memory networks for relation classification. In Proceedings of the 54th Annual Meeting of the Association for Computational Linguistics (Volume 2: Short Papers), volume 2, pages 207–212.

