
数据观察
数据集情况
训练集共7个表:
- base_info:所有企业的基本信息。
- annual_report_info:企业的年报基本信息。
- tax_info:企业的纳税信息。
- change_info:企业的变更信息。
- news_info:企业的新闻舆情信息。
- other_info:企业的其他信息。
- entprise_info:标签。
企业基本数据包含了所有企业的大部分信息,因此可作为模型训练所需的主要特征。其他数据仅包含部分企业信息,可通过处理挖掘出相关特征,提升预测正确率。部分企业存在数据缺失情况,可依据数据相关业务进行填充。
样本分布情况
由于是脱敏后的真实数据,存在非法集资的企业数量较少,因此正负样本比例不均衡样本主要特征集中在企业基本数据中,其他数据仅含样本较少特征。
数据类型情况
数据集中存在多种数据类型,包括数值型、字符型、日期型等。由于地址信息、变更内容等涉及隐私,因此对相关内容进行了脱敏处理。
base_info
这张表是训练集中最基本最重要的一张表,总共包含24865条数据,33个字段,其中14865条数据用于训练,剩下10000条用于A榜测试集提交。
信息统计:
1 | 字段名称 数据类型 空值数 空值比例 取值个数 字段含义 |
可以发现合伙人数、执行人数、兼营范围、中西部优势产业代码、 项目类型、实缴资本(外方)、注册资本(外方)、投资总额这几个字段空值率大于90%甚至全部为空;经营期限止、组织形式、经营方式、风险行业、企业类型细类、实缴资本这几个字段的空值率在50%到70%左右,上面这些字段的空缺比例较大,不好填充,可以考虑直接丢掉。行业细类代码、企业类型小类、从业人数这三个字段缺省略少,可以考虑填充一下。
annual_report_info
数据量:22550
信息统计:
1 | 字段名称 数据类型 空值数 空值比例 取值个数 字段含义 |
资金数额、成员人数、农民人数、本年度新增成员人数、本年度退出成员人数这几个字段缺失较多。该表数据只覆盖了8937家公司。
tax_info
数据量:29195
信息统计:
1 | 字段名称 数据类型 空值数 空值比例 取值个数 字段含义 |
虽然数据量接近3万,但仅有808家公司的税务信息。
change_info
数据量:45940
信息统计:
1 | 字段名称 数据类型 空值数 空值比例 取值个数 字段含义 |
news_info
数据量:10518
信息统计:
1 | 字段名称 数据类型 空值数 空值比例 取值个数 字段含义 |
新闻正负面性三种情况的数量如下:
- 积极:5350
- 中立:4133
- 消极:1035
other_info
数据量:1890
信息统计:
1 | 字段名称 数据类型 空值数 空值比例 取值个数 字段含义 |
entprise_info
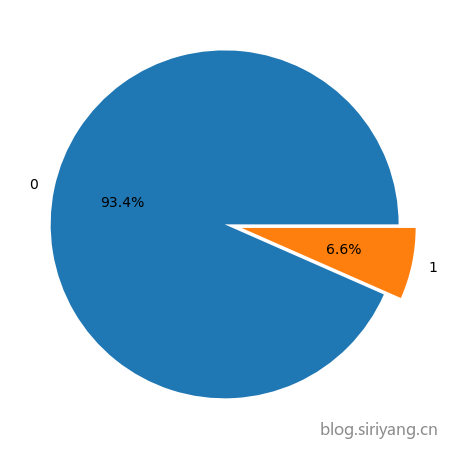
经统计,正负样本个数如下:
- 0:13884
- 1:981
正负样本比例约为1:14,正样本占比约为6.6%。
风险总结
企业非法集资相关风险主要有如下五类:
基本风险
- 基本信息:企业状态、企业类型、企业门类
- 经营资质:经营项目、经营范围
- 变更信息:变更事项、变更频度、变更内容
遵从风险
- 投诉举报:投诉举报次数、咨询次数、案值
- 案件信息:涉案次数、累计涉案案值、案由
- 法院诉讼:诉讼次数、累计执行标的
行为风险
- 产品信息:产品个数、产品描述、收益率
- 招聘信息:招聘人数、是否异地经营
- 知识产权:专利数量、作品个数
族群风险
- 族谱信息:和其他非法集资企业的关联关系
舆情风险
- 舆情信息:负面新闻次数、负面新闻
其中族群风险这里类的信息由于不便统计,在这次比赛数据中没有涉及。
评价指标
赛题的评价指标一开始为AUC,计算公式如下:
$$AUC=\frac{\sum_{i\in positiveClass}rank_i - \frac{M\times (M+1)}{2}}{M\times N}$$
M为正样本数,N为负样本数,ranki 为 第 i 个正样本所在的位置。
由于AUC线上提交结果太好,很难进一步提升;提交结果区分度较低,难以作为比赛判断标准
,后来改为F1-score:
$$
P=\frac{TP}{TP+FP}\\
R=\frac{TP}{TP+FN}\\
F1=\frac{2\times P \times R}{P+R}
$$
实际计算的时候F1带有权值,其中精确率的权重更高,具体权值官方未公布。
建模思路
V0.0:0.82623517166 (F1);0.98584349(AUC)
直接简单粗暴的将base_info中的非数值型字段丢掉,对于存在缺省值的字段也不做填充处理,使用lgbm五折交叉验证进行训练,最终线上得分0.82623517166 (F1);0.98584349(AUC)。
在没有提前任何额外特征和处理的情况下,直接使用基础信息进行训练基本大家都在0.98以上,官方检查数据后表示维持数据的真实现状,不修改数据集和评价指标。之所以能轻易取得这么高的分数的原因一是因为基础信息字段较多,信息表征已经较为丰富;第二就是因为数据极不平衡,正样本很少。
1 | feature importance: |
V0.1:0.80278669547(F1);0.98312726953(AUC)
v0.0模型的特种中所有分类特征都是直接作为数值类型放进lgbm中进行训练的,lgbm可以设置分类特征,于是将那些分类特征设置为category类型进行训练,但是最终线上得分反而下降。
V1.0:0.82279875710 (F1);0.98660033(AUC)
在v0.0的基础上,对base_info的industryphy字段进行编码(从1开始),去掉midpreindcode特征;
然后对news_info表分别提取计算各个公司积极、中立、消极新闻的个数,然后左连接到特征总表;
在other_info表中统计各个公司个字段的总和,然后左连接到特征总表。
V2.0:0.82816986543
在V1.0特征的基础上,将lgbm五折交叉验证换成catboost五折交叉验证,分数提升0.006左右。因为该数据集中存在大量的分类特征,所以使用catboost效果会更好一点,从名字也可以看出该模型算法对分类特征的处理较为擅长。
参考资料
V2.1:0.83284844
因为catboost的分类特征字段类型只能为int或者string,之前一直将所有分类特征为object的编码为int,然后合着float的全部再强转为int。由于担心float强转int的时候因为截断或者什么的造成信息丢失,所以现在统一转为string。在这里还遇到一个坑,之前转换的时候我直接写的train[i] = train[i].astype('string'),但是实际转换出来在训练的时候会报错:
1 | TypeError: Cannot convert StringArray to numpy.ndarray |
正确的做法应该写成train[i] = train[i].astype('str'),用str转换出来的是字符串,string转换出来的是字符串数组,二者有点区别。
接着对base_info表的opform特征进行分桶。
1 | opform: |
将该字段的各个取值的数量统计信息可以发现,10、01-以个人财产出资(01应该和他是同一类)的占比很大,其他几类的数量相比起来就特别少,所以我以此将他们分为4类进行训练。分桶以后的比例为:
- Nan:15865
- 10:8186
- 01:734
- other:80
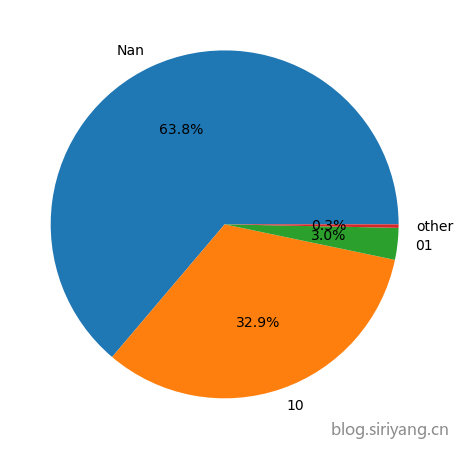
最终训练出来线下验证集分数有所上涨,五折交叉以后F1的平均值和方差分别为0.839510和0.020048,线上提交成绩为0.83284844,在V2.0的基础上上涨0.0046。同时该特征的特征重要性也相对较高。
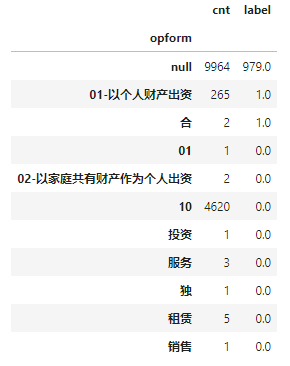
但是再次观察训练集范围数据标签与各个取值的共现率,发现标签几乎都在空值数据项上,和该字段相关性不大,可能是运气好把分数抖上去了:
V2.2:0.83620532
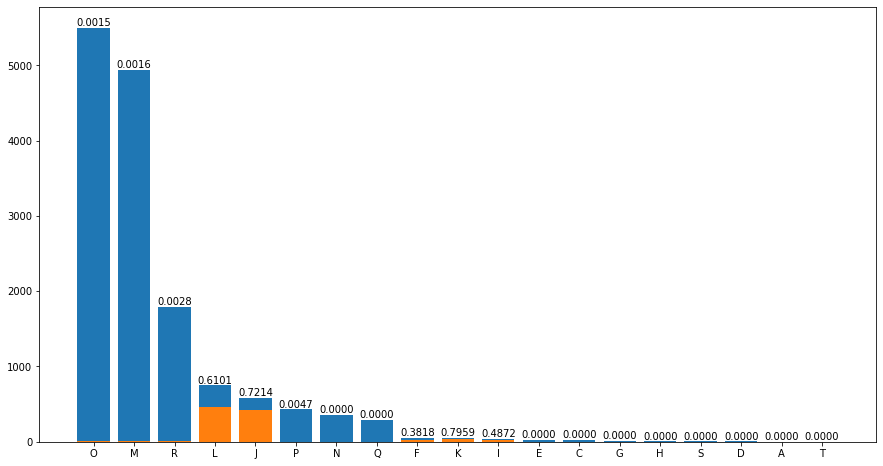
industryphy
industryphy在模型的特征重要性中最高,观察该字段的数据分布可以发现,['L','J','K','F','I']这几个类别中非法集资的企业相对较多,['O','M','P','R']几个类别的非法集资企业先对较少,剩下的类别非法集资企业数量为0。于是以此将他们分桶为三类。
opfrom
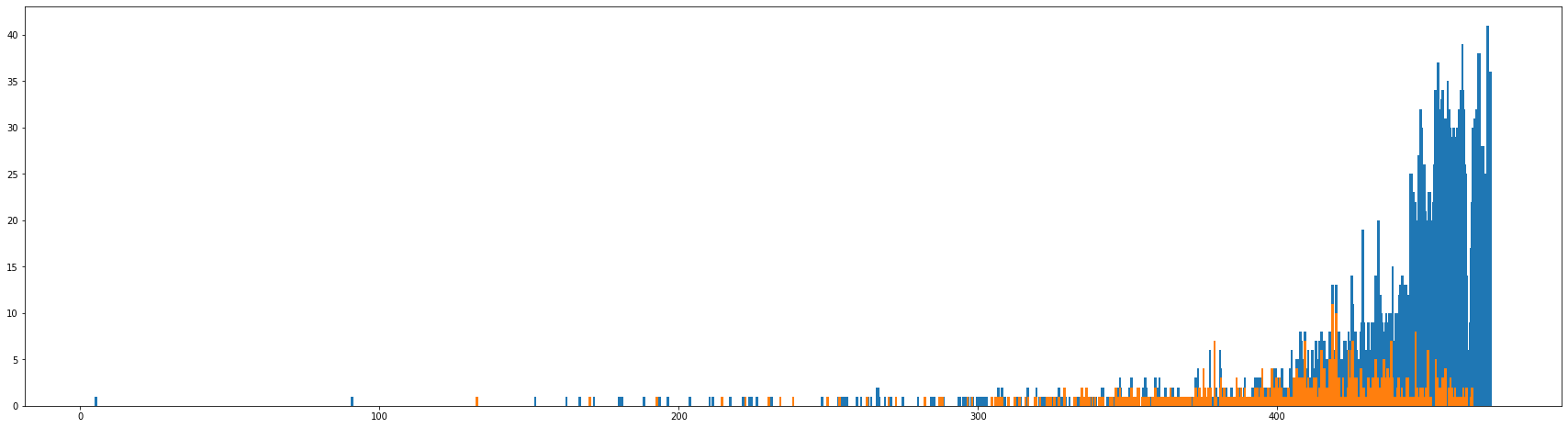
将opfrom字段转换为datetime格式,然后提取其年份特征。绘图后观察到,随着年份的增加非法集资企业的数量也来越多,在15、16年左右达到鼎盛,之后数量又开始逐渐下降。很明显年份与非法集资企业的数量有很强的线性关系。

由于有一些企业的注册时间实在11月、12月这种年底,相对更靠近下一年,猜想如果按照月份进行划分的话可能会得到更为细腻的信息。将各公司注册时间与1981年1月1日做差求取其月数差值,绘图后可以观察到月份差值与非法集资企业的数量分布相对更为散乱一些,将该特征放入模型进行训练线上得分也有所下降,所以还是直接用年份进行训练,年份的重要性排名第二。
regcap
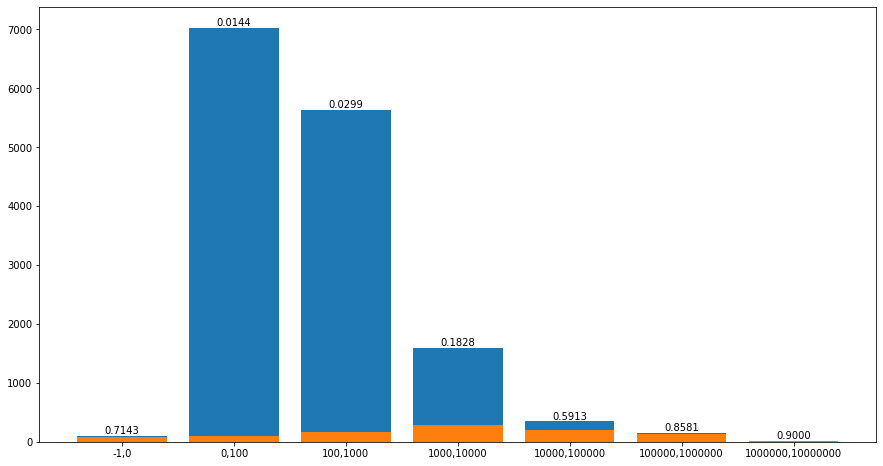
regcap直接进行训练其特征重要性也很高,排名第三。通过数据观察可以发现,在非空值中最小值为0,最大值为5000100,而大多数数据分布在0到10000以内,那些大数值数据量很少。如果直接将该字段作为数值类型进行训练效果必然没有那么好,所以还是采取分桶的方式,直接以10倍的数量级进行划分。将分桶后的数据绘制观察可以发现非法集资企业的数量与各数量级之间也有比较明显的线性关系。
除上述几个较强的特征以外,还加入了人数特征之间两两的差值,以及注册资金与各人数特征之间的商。这几个特征加入以后模型分数也有所上涨,其特征重要性排名中下左右,还是有一点用,个人直观的理解就是那种注册资金很高但是人很少的公司多半都有问题。
最后使用单折的catboost进行训练,将数据集随机打乱并按照7:3的比例划分为训练集的验证集以用于早停。线下验证集得分0.8283185841,多次实验下来,线下线上得分变化趋势并不一致。
v2.3:0.83733201822
自从水哥公布baseline以后已经人均0.84了,我下下来试了下也跑到了0.842的样子。
尝试把水哥的特征悉数迁移到我的模型上来,然后使用五折catboost进行训练,最终得分0.837。
Baseline下载

