基础知识学习
2020.09.24
本次参加的竞赛类别为NLP下的NER(命名实体识别)任务,由于对于该类任务还没有任何经验,所以现在网上搜集一些资料进行学习。
- 流水的NLP铁打的NER:命名实体识别实践与探索
- 如何用简单易懂的例子解释条件随机场(CRF)模型?它和HMM有什么区别?
- BiLSTM模型中CRF层的运行原理-1
- 工业界如何解决NER问题?12个trick,与你分享~
除了上述文章以外还在B站上找到了一个和本次题目很类似的命名实体识别项目教程,使用的双向LSTM+CRF:
双向LSTM只能抓到前后十几个字的信息,RNN只能抓到前后三四个字的信息,不能处理长文本。
样本增强,先把一个长句子拆成短句子,然后把相邻的两三个短句子组合成一个长句子。
2020.09.26
分词后词的边界和字的拼音都可以作为特征。
要获取拼音、偏旁部首特征,需要安装cnradical工具包:
1 | pip install cnradical |
2020.09.27
早期命名实体识别使用正则来做,现在使用神经网络可以根据上下文来进行识别,即使打错字或者出现新的病也能识别出来。
将出现频率较小的元素从映射字典中去掉以作为未登录词,否则在测试集中出现新的未登录词将难以预测处理,即仅保留频率较高的元素。
循环神经网络可以处理不同长度的不同批次的数据,但是同批次的数据要构成一个矩阵,必须要长度一致,所以使用PAD进行填充。
每个批次数据在进行填充的时候是以本批次中最长的那个句子作为标准,将句子排序后长度差不多的句子会在一起,这个时候再去分批次每个批次数据的长度就是接近的。填充的部分是不用进行训练的,如果长度差异过大的句子在一起训练,短的句子要等待长的句子,会托慢速度。
赛题分析与数据观察
数据集总共2000条文本,其中0到999有标注,作为训练集;1000到1499为初赛测试集,1500到1999为复赛测试集。
目前对训练集和初赛测试集做数据统计有如下结果:
实体信息统计
由题目可知,实体类别总共有13种,分别为:
1 | ['DRUG_EFFICACY','PERSON_GROUP', 'SYMPTOM', 'DRUG_DOSAGE', 'DRUG_TASTE', 'SYNDROME', |
对其类别数量进行统计:
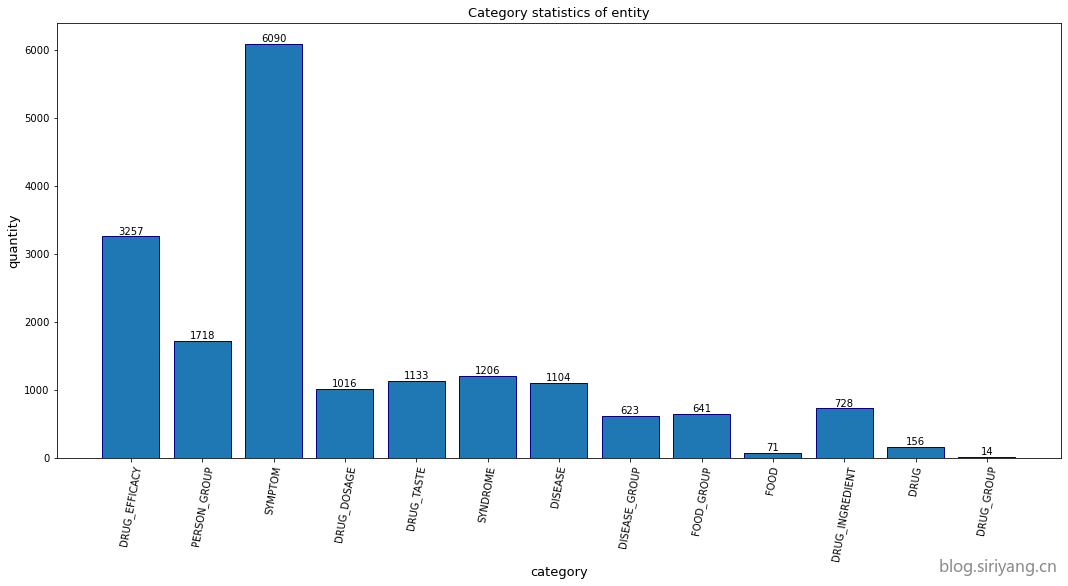
数量最多的一种实体是SYMPTOM,有6090个;数量最少的一种实体是DRUG_GROUP,有14个。样本不平衡。
对出现过的实体文本长度进行统计:
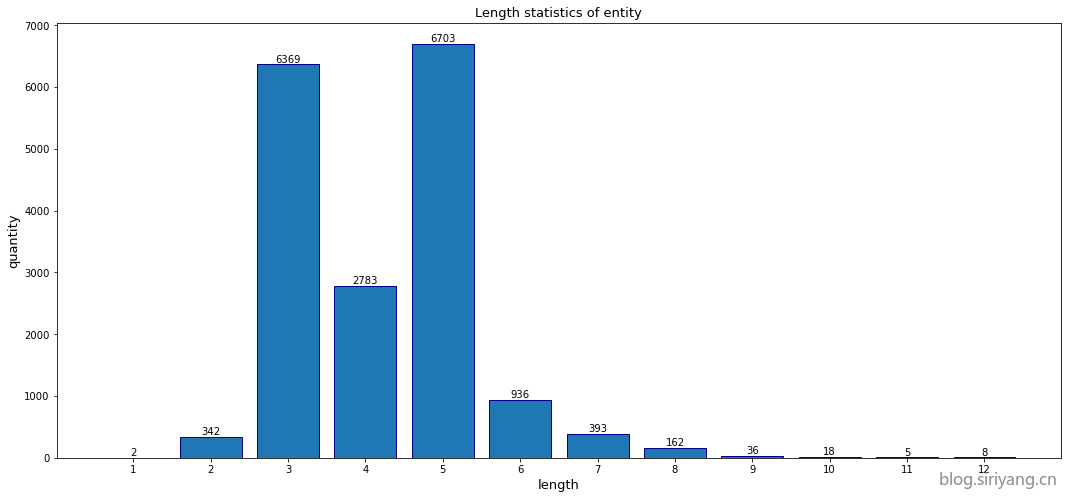
最长的实体文本有12个字符;最短的实体文本只有1个字符,一共有两个。
1 | T4 DRUG_TASTE 16 17 涩 |
文本信息统计
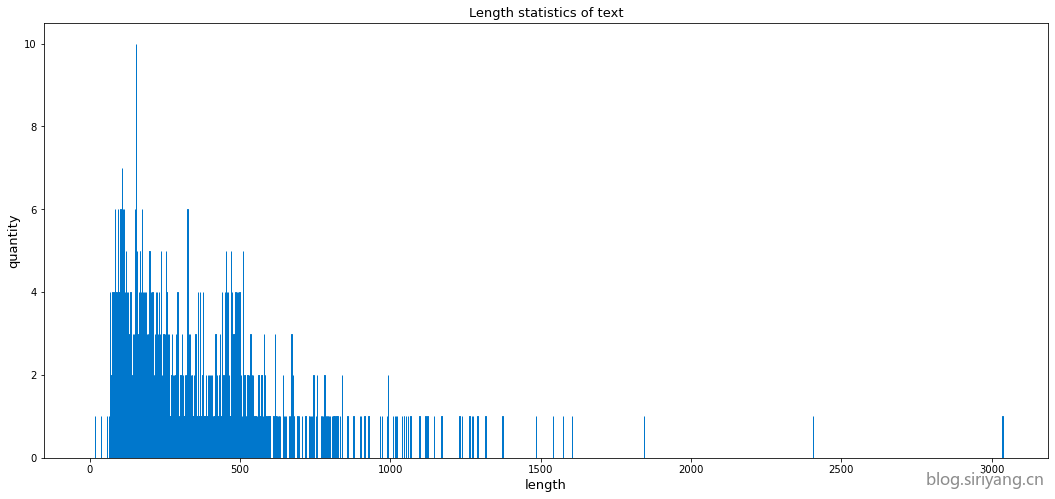
统计训练集的文本长度:
统计测试集的文本长度:
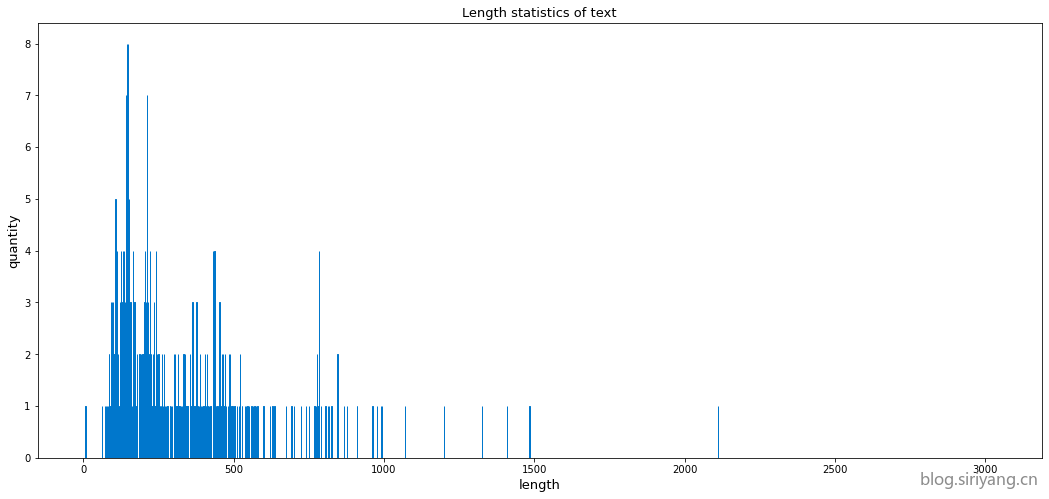
训练集中最长的文本有3036个字符,最短的文本有17个字符;测试集中最长的文本有2111个字符,最短的文本有6个字符。训练集和测试机的文本长度分布相对一致,大多都在250左右。
实验记录
2020.10.06
使用滑动窗口对数据进行切分,仅在文本长度小于预设的最大长度MAX_LEN时使用滑窗进行切分。窗口大小WINDOWS小于MAX_LEN时,滑窗是有交集的切割,否则为无交集的切割,且WINDOWS应小于等于MAX_LEN。
提交01
- 滑动窗口有交集,
MAX_LEN=512,WINDOWS=100; - 使用BIO进行打标;
- 使用LSTM+CRF进行五折交叉验证训练;
- 线上得分:
score:0.7093 f1:0.7093 p:0.6639 r:0.7615
提交02
- 滑动窗口无交集,
MAX_LEN=512,WINDOWS=512; - 使用BIO进行打标;
- 使用LSTM+CRF进行五折交叉验证训练;
- 线上得分:
score:0.7139 f1:0.7139 p:0.6714 r:0.7621
使用无交集切割相比有交集切割分值有所上升。
2020.10.09
提交03
- 滑动窗口有交集,
MAX_LEN=512,WINDOWS_SIZE=502,WINDOWS_STEP=100; - 使用BIO进行打标;
- 使用BERT+CRF进行单折训练;
- batch_size=5;
- epoch=10;
- 线上得分:
score:0.6754 f1:0.6754 p:0.6221 r:0.7386
使用的一台Quadro P4000的服务器进行训练,显存只有8G,batch_size最高只能设到5。
提交04
- 滑动窗口有交集,
MAX_LEN=512,WINDOWS_SIZE=502,WINDOWS_STEP=100; - 使用BIO进行打标;
- 使用BERT+CRF进行五折交叉验证训练;
- batch_size=5;
- epoch=20;
- earlystop=2;
- 线上得分:
score:0.7385 f1:0.7385 p:0.6737 r:0.8171
环境问题
2020.10.05
为了在实验室服务器上进行深度学习模型的训练,需要安装tensorflow。但是服务器没法访问外网,就只好在pipy下载离线安装包手动安装。我下载的版本是tensorflow-2.0.0-cp36-cp36m-manylinux2010_x86_64.whl,结果在安装时报错不支持当前平台。通过百度查阅资料找到解决方案,只需要将文件名修改为tensorflow-2.0.0-cp36-cp36m-manylinux1_x86_64.whl就行了。
参考资料:
2020.10.06
在导入tensorflow的时候遇到报错:AttributeError: module ‘tensorflow’ has no attribute ‘reset_default_graph’
解决方案为,将:
1 | import tensorflow as tf |
替换为
1 | import tensorflow.compat.v1 as tf |
参考资料:
2020.10.08
在训练bert的时候遇到报错:RuntimeError: cuda runtime error (38) : no CUDA-capable device is detected
原因是代码中CUDA_VISIBLE_DEVICES值为1,而我是单卡训练的话应该为0。
1 | -os.environ["CUDA_VISIBLE_DEVICES"] = "1" |
参考资料:

