2020.06.05
正式赛训练数据一共有三张表,分别是历史运单GPS数据、历史运单事件数据、港口坐标数据。其中其主要作用的是历史运单GPS数据,该数据文件解压后共21G,有1.4亿多条数据,且字段也很多。为了理清各表之间的关系,作如下关系图:
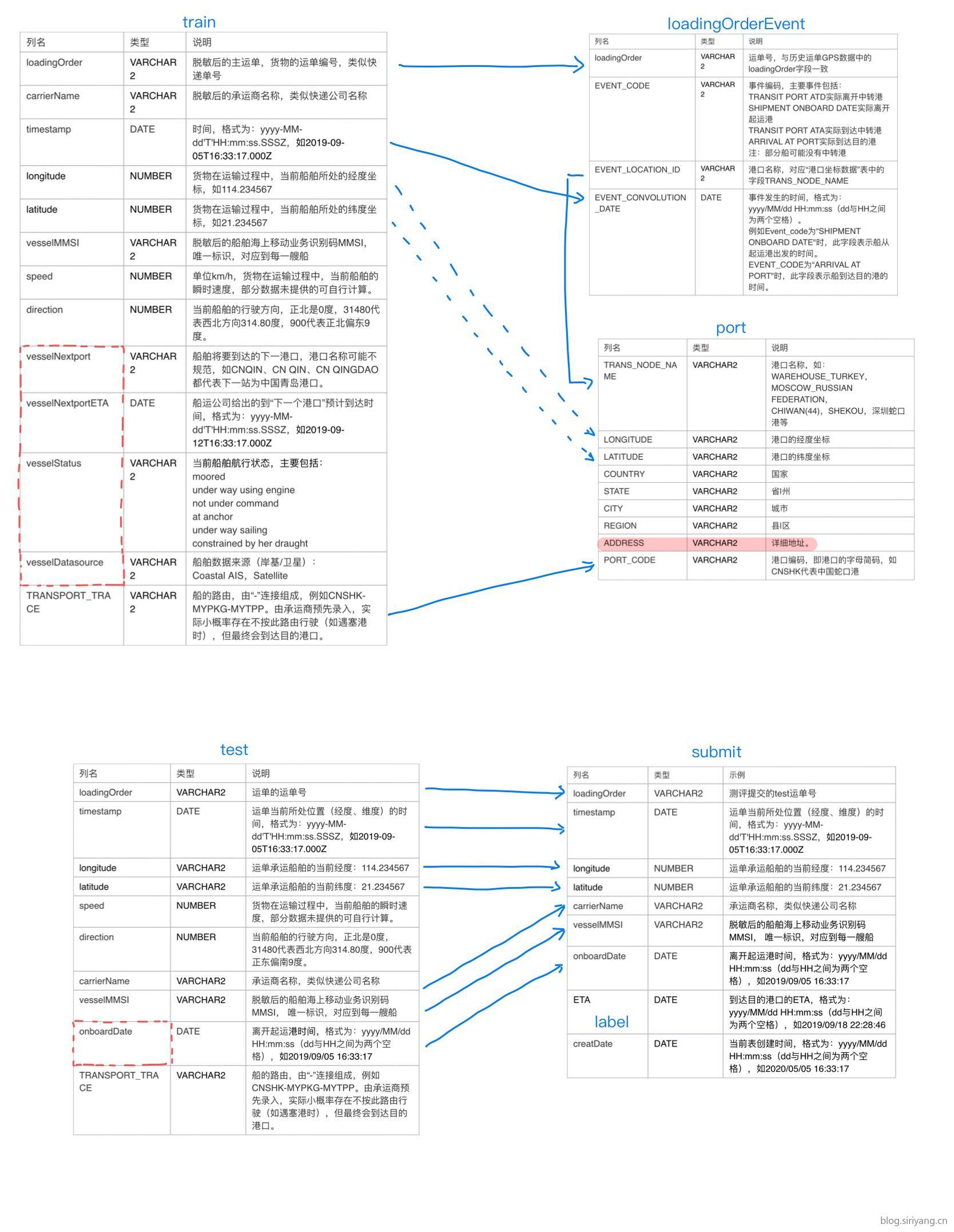
各表的数据大致情况如下:
历史运单GPS数据:
1 | RangeIndex: 147907541 entries, 0 to 147907540 |
历史运单事件数据:
1 | RangeIndex: 1011936 entries, 0 to 1011935 |
港口坐标数据:
1 | RangeIndex: 2456 entries, 0 to 2455 |
测试数据:
1 | RangeIndex: 45456 entries, 0 to 45455 |
发现历史运单事件数据中有大量重复值,于是进行去重:
1 | Int64Index: 115729391 entries, 0 to 147907426 |
去重总共去掉了32178150条重复数据,将去重后的文件保存,文件大小为15G。
使用姜大德大佬分享的baseline进行初步尝试和学习。一开始投入1000w数据进行训练,线上得分96406.3440。之后尝试将全部数据都投入训练,最后得分45817.8448。不过在把数据全部都放进去之前,需要使用万金油队大佬的baseline算法优化方法,否则原baseline算法的数据处理速度贼慢,优化以后17分钟就好了。
使用baseline的过程中发现一个问题,之前的训练设置了早停参数,但是每次的最佳训练轮数都是1。经分析,该早停的衡量标准是取决于我们评估函数越大越好,因为我们的mse是一个逐渐减小的过程,所以训练每次都在第一轮就停止了。解决方案很简单,直接把自定义的评估函数返回值取反就行了。
1 | def mse_score_eval(preds, valid): |
2020.06.06
参考本周周周星第二名的经验帖,去掉重复数据,将标签由秒改为小时,再使用昨天修改好的mse评估函数进行训练,最后训练结果在训练集和验证集上都拟合到2900左右,但是提交测试集预测结果后,线上的得分却又20多万。经分析,导致在训练集、验证集上拟合较好,但是在测试集上效果不好的原因是,我们的训练集和验证集都是在训练数据上进行提取和划分出来的,训练数据中包含有完整的gps路径信息,但是在测试集中只给出了一部分,如果采用相同的方法进行提取特征,那测试集提取出来就会有很大偏差。
2020.06.07
暂时先放下特征提取和训练的工作,把工作重心放到数据清理上。首先对数据进行去重,然后筛选出有路由的数据,之后准备对比订单的随后一条GPS数据与目的港看的距离,以此判断该订单的GPS数据是否完整。同时也去掉GPS数据过少的订单。
2020.06.08
做了一天的数据清洗,在昨天的基础上通过对比订单第一条和最后一条GPS与出发港和目的港位置是否在30km范围内来进行数据筛选,最后选出了6000条订单。对目的港和出发港的具体进行了重新计算,累计到达中转港的每一段长度,而不是目的港与出发港的直线距离。在baseline特征的基础上今天加上港口距离特征,依然使用过lgbm五折交叉验证拟合训练,线上成绩由之前的20万下降到135877.1882,看来数据清洗还是有点作用。之后尝试将迭代次数下降到100,线上成绩为124336.1985。
2020.06.09
搞了两天总算把数据清洗做完了,在昨天的基础上对数据进行了下采样,提取了每条订单前30%的gps数据,然后提取了平均速度、最大速速、速度中位数、已经走的距离、已经走的时间、剩下的距离以及已经走的距离占总距离的比例这几个特征。使用lgbm,并划分验证集进行训练,最终线下验证集得分6200,线上得分8327.6060。使用xgb进行训练,线上得分8985.9711。最后将验证集一并合并到训练集中进行使用lgbm训练,线下训练集得分5400,线上得分7856.0160。
2020.06.12
仅将数据过滤范围缩小到20km以后,使用lgbm不划分验证集进行训练,最后线下得分5667,线上得分7983.9554。
2020.06.14
仅将数据过滤范围缩小到10km以后,使用lgbm不划分验证集进行训练,最后线下得分4863,线上得分7172.1768。之后继续尝试将范围缩小到5km,线上得分上升到8163.1949。
2020.06.15
将过滤范围限定在10km,然后分别下采样30%、40%,全部加入训练,交叉验证得分3417.16,线上的分6170.7404。
2020.06.16
在昨天的基础上,继续加入25%的下采样,去除所有速度为0的gps数据,全部加入训练,交叉验证得分2433.2,线上的分5329.6254。
之后尝试加入预计剩余的时间、预计总共走的时间两个特征进行训练,线上得分下降到5140.6562。
2020.06.17
添加vessel_id、trace_id、carrier_id三个分类特征,去掉出发时的月份特征,线下交叉验证得分1220.57,线上得分5679.9296。
2020.06.18
感觉数据集线下和线上差异越做越大了,卡在5000分段一直下不去,和师兄交流以后感觉还是前期数据观察不到位,清洗出来的数据还存在很大的问题,准备从头再来一遍,对航线进行可视化观察。
测试集
1、测试中订单存在到达目的港以后还继续航行的情况
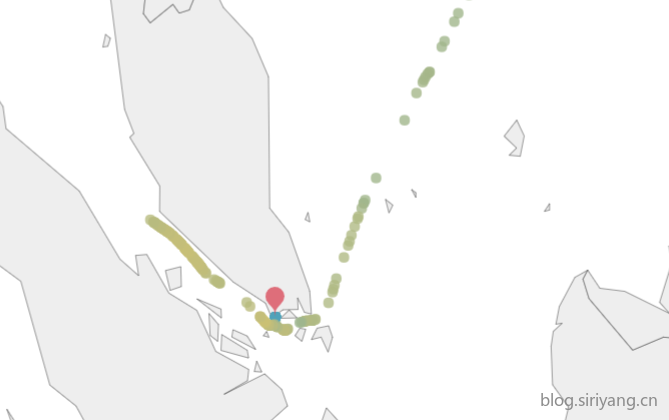
2、测试中订单的GPS数据有些并不是从出发港开始取的,而是中间的某一段
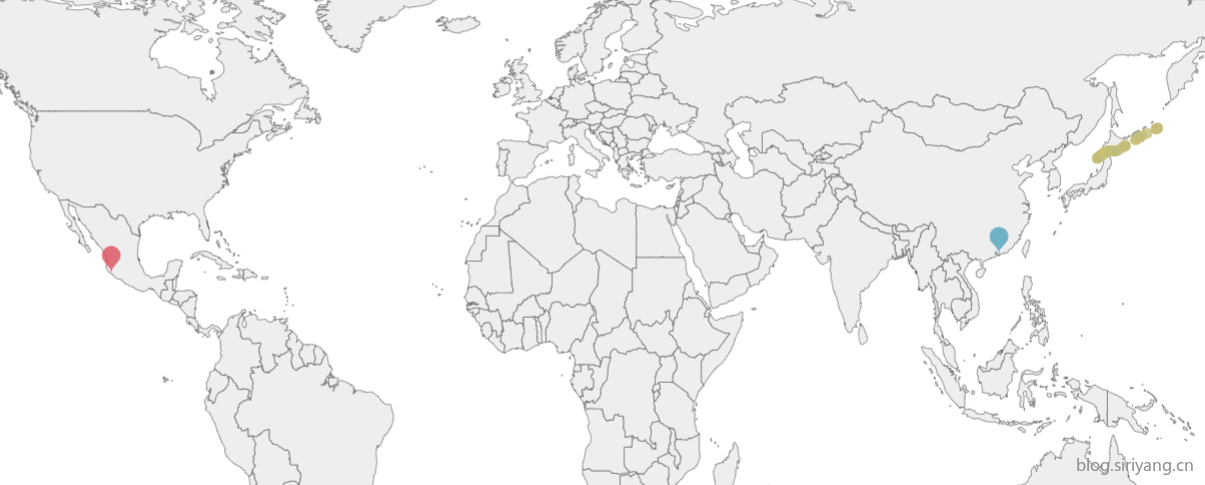
3、虽然测试集中的订单路由都没有中转港,但是从可视化来看仍然有靠港停泊的情况

4、有些订单GPS数据一直在走,但是速度为0,在对速度进行特征值提取的时候可以把这些点暂时忽略掉

5、有一个订单走了一段以后又倒回去了一截
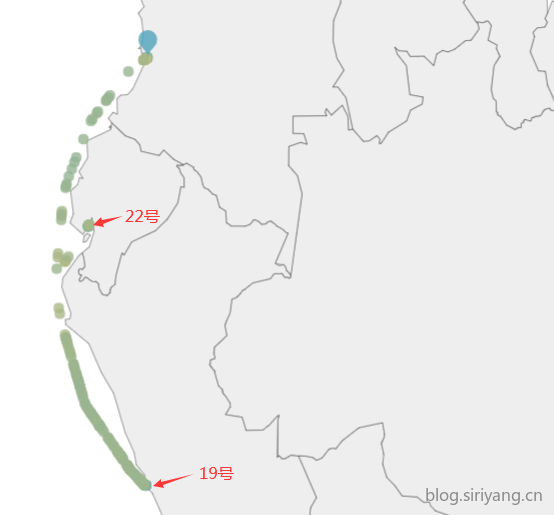
6、有个别订单只有初始港附近有数据点,而且红色箭头所指的地方密密麻麻一堆速度为0的点

2020.06.19
训练集
塞港事件较为频繁,有的一塞就是两到四天,停泊范围在20km到60km不等
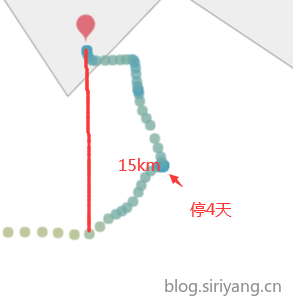
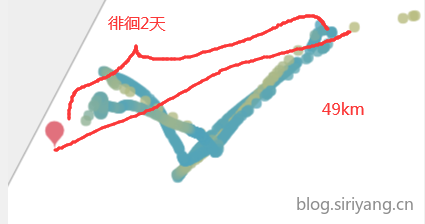
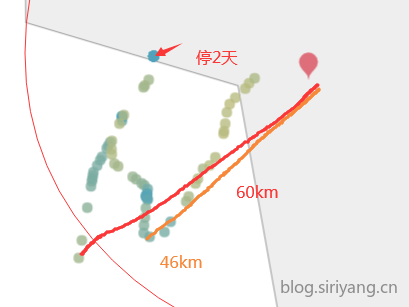
更换方案,采取预测最后一个坐标点到终点的时间。对数据集进行重新观察和清洗,先取出最后一个坐标里终点在50km范围内的订单,然后清除五十公里范围内的数据以尽可能的去掉塞港数据,再筛选出最后一个坐标距离终点在60km范围内的订单。在之前的基础上清除初始坐标距离出发港10km范围内的数据,然后筛选出初始坐标距离出发港20km以内的订单,此时大概有5000条订单。分别按照1%、10%、20%、30% ··· 80%、90%、99%的比例进行采样组合到一起,打标时计算采样后订单最后一个坐标距离数据清洗后订单最后一个坐标的时间差,因为最后一个订单距离目的港至少还有50km的距离,所以在标签上加1小时的偏移(之后这个值还有待调整)。
对于测试集也做了一定的处理,因为有几个订单到达目的港以后又继续走了一段距离,所以手动把这段距离给截取掉了。
使用之前版本的参数和特征进行训练,最终线上得分3157.5143,线下验证集得分548.6。
2020.06.20
在昨天的基础上进一步对训练集进行处理,将存在两点间时间间隔大于24小时的订单删掉,去除时间间隔小于5分钟的GPS数据点。经过处理后,剩下大概3800条订单,数据量500万条。通过控制采样点的时间间隔可以使数据分布更为均匀,有利于后期采样。采样率依然按照1%、10%、20%、30% … 80%、90%、99%的比例进行采样组合到一起。
使用之前版本的参数和特征进行训练,最终线上得分1991.0731,线下验证集得分200。
2020.06.21
在上个版本的基础上,将订单末尾的截取范围扩大到60km,保留截取后最后一个坐标仍在80km范围内的订单,此时剩下3500条订单。在打标的时候将时间偏移扩大到2小时。
最终线上得分1748.9863,线下验证集得分237.6。
2020.06.22
将采样率改为10%、20%、30%、40%、50%、60%、70%,线上得分1443.8652。不过线上线下得分差异开始变得不稳定。
2020.06.23
将feature_fraction由0.6调整为0.5,线上得分1246.3547。由于线上线下得分变化趋势并不一致,所以调参只能提交以后通过线上得分的变化来判断,没法进行网格搜索。
2020.06.24
进一步调参,将num_leaves由36改为37,线上成绩得分1128.1393。
2020.06.27
在B榜数据的基础上更新船只、路由、承运商的id编号,然后使用和A榜同样的数据处理方法处理B榜数据然后进行预测,线上的分1099.33,可以看出模型较为稳定。
2020.06.30
将1099和1024的两个模型进行均值融合,最终B榜线上成绩963。
初赛结束,成功晋级复赛!复赛线在2928.51。
![]()

