2020.04.24
v0.0.1 版本:44.4365
该版在baseline的基础上进行修改。baseline中将所有数据按照weekday和timeindex对五和张衡路口各个方向的数据进行均值聚合,按照赛题的要求是预测该路口各个方向的总车流量,所以这种做法从根本上是错误的。同时将数据简单的归结为weekday和timeindex两种特征信息,也丢失掉了原数据大量的信息要素。
所以在此基础上,我保留每一个项数据的datetime信息作为临时特征进行特征提取,在所有特征提取完之后再将其drop掉。将原baseline数据聚合的代码删除,改为按照datetime、weekday和timeindex三个主键将同一路口各个方向的数据进行求和,此时数据集大小变为原来的四分之一。然后在此基础上提取了is_workday、monthday和is_festival三种简单特征值,其中monthday将数据压缩到0-1范围内。
仍然保持原模型参数进行训练,将number作为标签,最终训练结果如下:
1 | MSE: 379.7069 |
v0.0.2 版本:60.7249
该版在v0.0.1的基础上进行修改。首先将所有数据作为历史数据,提取当前时间片的均值、最大值、最小值、中位数和当前曜日当前时间片的均值、最大值、最小值、中位数。然后相当对于上一个版本较大的改动是模仿baseline去除number字段,而将number_weekday_timeindex_mean作为标签。
仍然保持原模型参数进行训练,最终训练结果如下:
1 | MSE: 2.7094 |
可见均方差和线上评测成绩都有较大提升,其中number_weekday_timeindex_median和number_weekday_timeindex_max两个特征值的权重尤为突出。
在下一个版本中准备加入之前提取的天气数据,然后考虑调整现在的数据集划分方式。当前是直接从所有提取好特征的数据集中直接随机划分的训练集和测试集,接下来应该考虑时间关系,按时间窗口的方法将数据集先划分为训练集和测试集,再进行特征提取。
2020.04.25
v0.0.3 版本:65.1086
突发奇想,将v0.0.2版本的number_weekday_timeindex_mean标签换为number_timeindex_mean会怎么样,没想到测试结果又有大幅度上升:
1 | MSE: 1.5327 |
2020.05.01
v0.0.4 版本:70.0916
学习大佬们的经验,选取最具代表性的数据,于是果断把春节假期以及假期前加班的两天的数据丢弃不用。然后对每天的数据做了可视化分析:
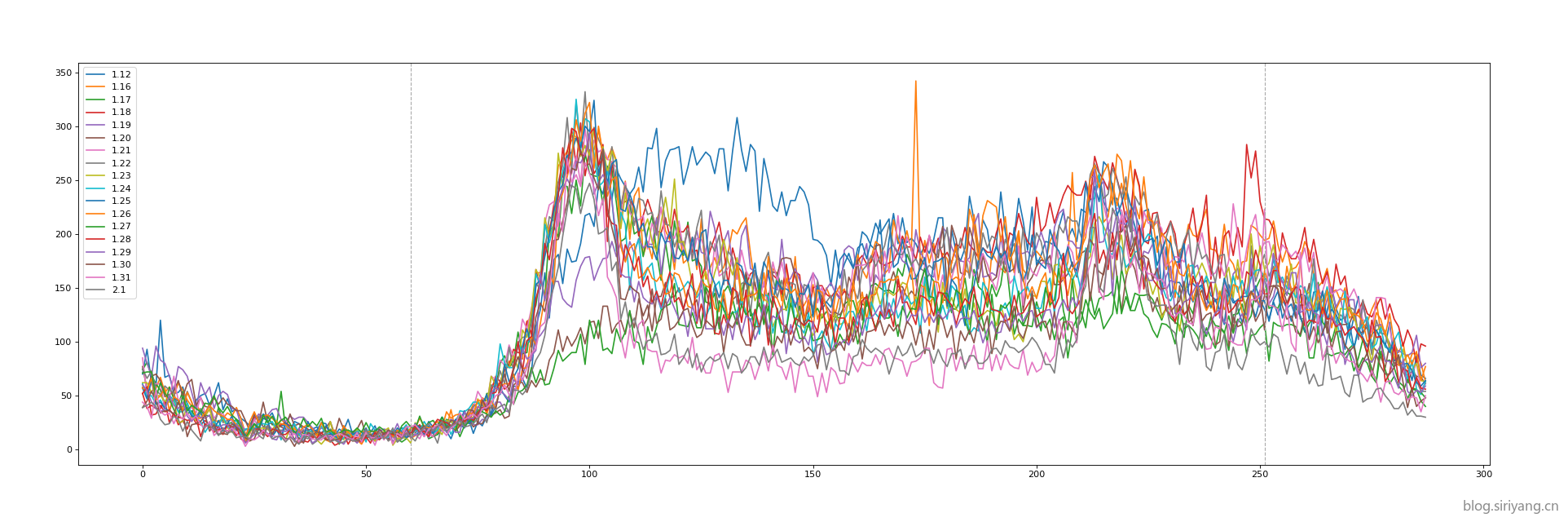
上图是1月12号至1月31号的数据,去除了具有缺失值的几天。考虑到要预测的两天都是工作日,就算是情人节那天应该也不会放假,所以决定将周末数据和部分有异常离群数据的天数去掉。最后得到了下面这张较为规律的图像:
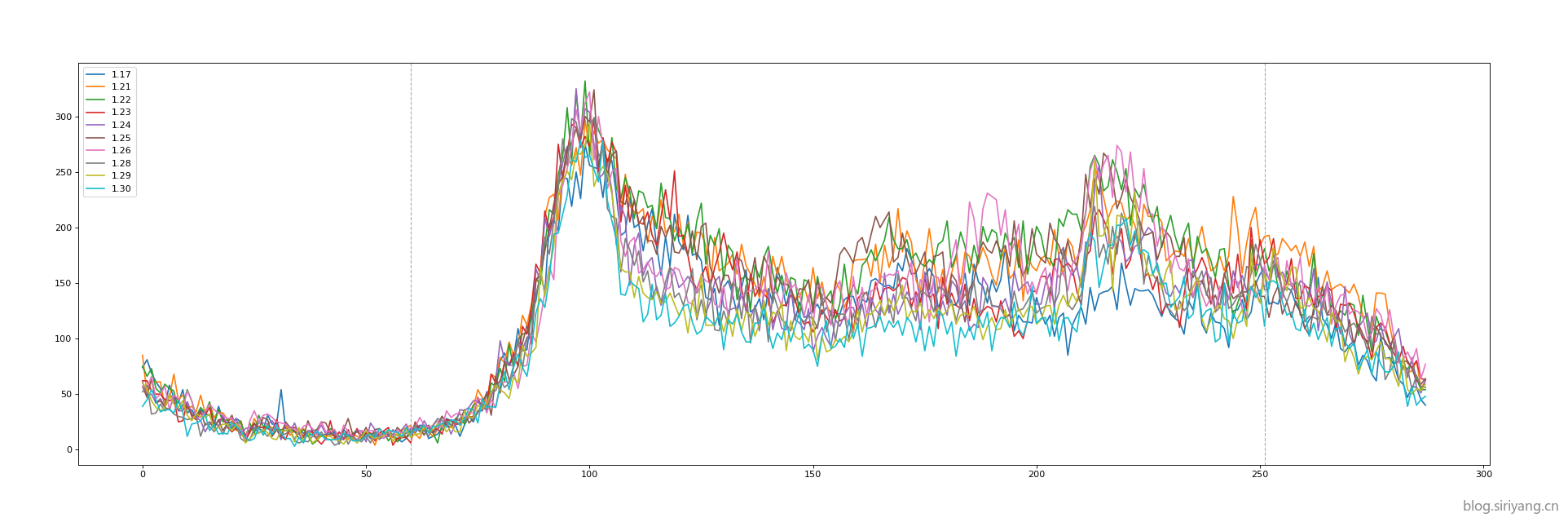
数据经过筛选以后我们只剩下了9天的数据,接下来就使用这9天的数据进行训练,由于都是工作日,所以之前的monthday、is_festival、is_workday三个特征就被我去掉了,并且在上一个版本中这三个特征的重要性也是0,并没有起到作用。
由于时间比较紧,还是使用的随机抽取的方式划分数据集,下一个版本再进行时间窗口的划分,并考虑引入官方的评分方法。
不出所料,线上成绩果然有不小提升:
1 | MSE: 2.2497 |
2020.05.03
v0.0.5 版本:67.3635
这两天在观察数据可视化图像的时候发现周六的流量并不低,并且晚上10点左右还有一个小高峰,突然恍然大悟,华为是996啊。哎,看来自己还是太年轻,还是学校上课作息那种思维…😞
然后将周六数据加入数据可视化再观察以后发现整体数值还是要偏低一点,大趋势差不多,估计周末leader们还是不上班吧。😂
观察半天只发现1月19号这个周六的数据与平时工作日偏差不大,将这天的数据加入到训练集中训练以后,发现MSE下降到了1.1114。然后将模型提交判分,最后得分为70.0850。这个分比上次低了一丢丢,但是这点差距几乎可以忽略。但为什么MSE又下降了一倍,但是最终结果却并没有提高呢。于是我开始思考一个问题,将均值作为标签也许一开始就是个错误的决定,虽然通过训练拟合的越来越好了,但是毕竟不是真实值,即使完全一样也会有误差。
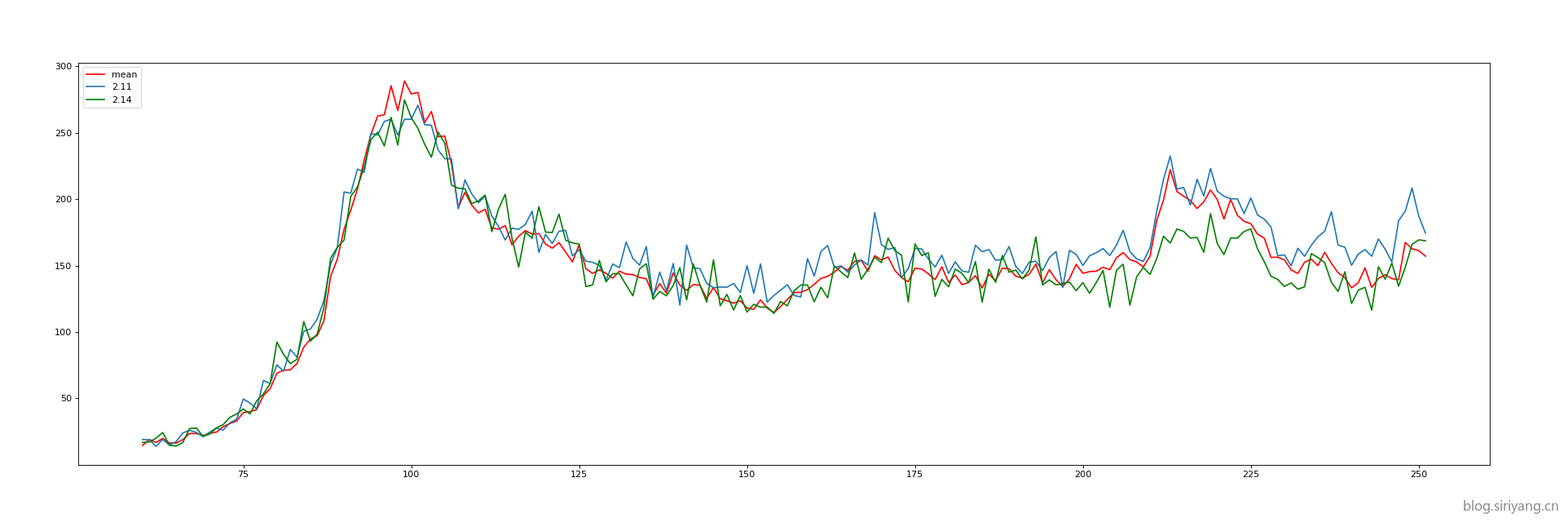
下面两张图分别是数据集均值的曲线和2月11号与2月14号的预测曲线:
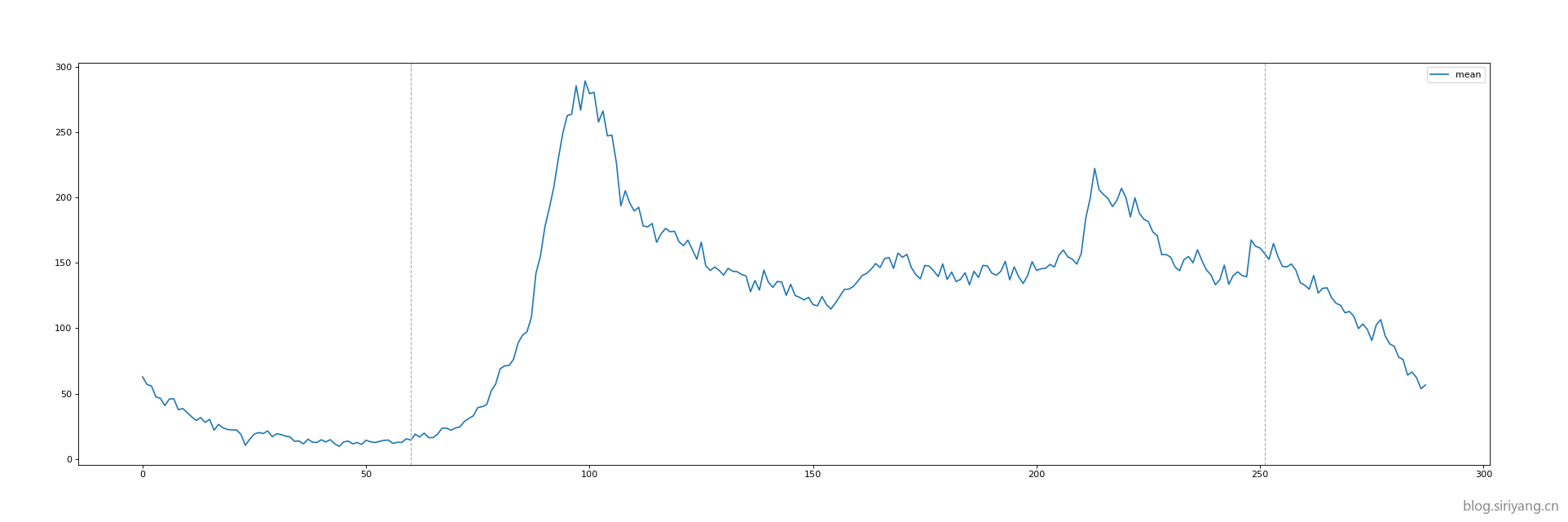
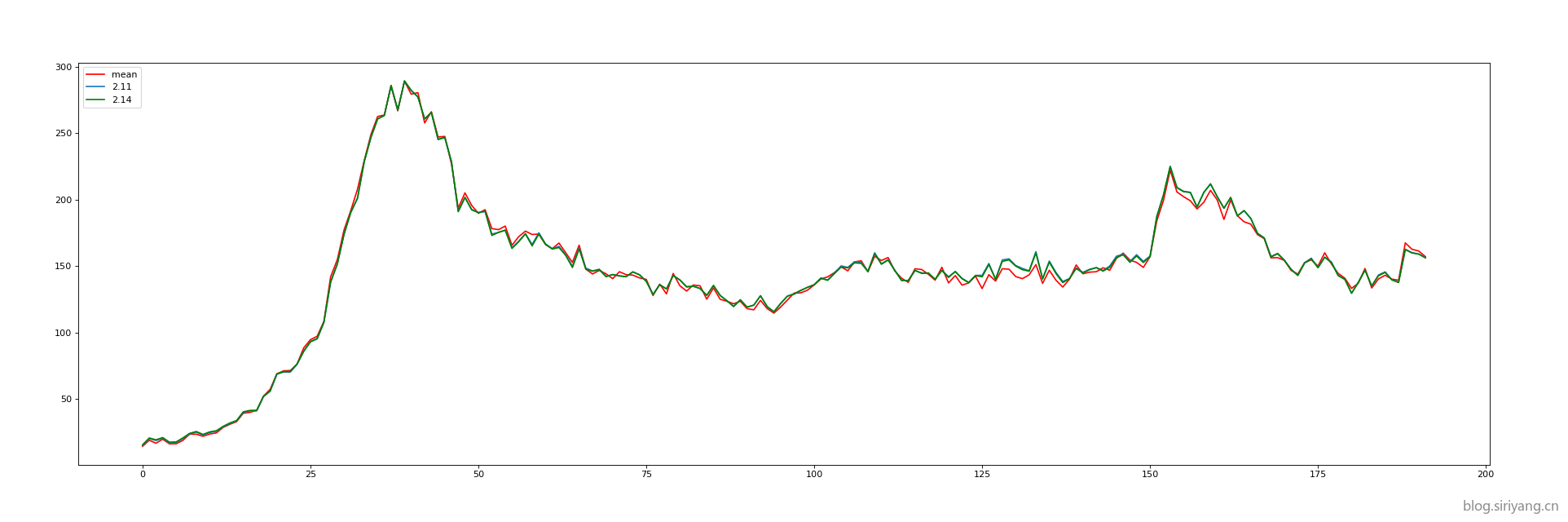
可以发现,11号与14号的预测结果完全一样,并且与均值曲线也拟合的非常接近了。该模型的上限就是这条均值曲线了,再训练下去估计也不会再有什么长进,预测数据的误差几乎就等于均值曲线与真实值的误差。
同时我们分析线上评分标准可以知道,有40分时来源于预测数据的变化趋势,而该均值曲线与真实值的趋势应该是大体相当的,所以最终得分70分中应该有绝大部分来自于这40分,而与真实值误差的60分那部分应该得分不多。
所以说接下来还想要有所提升只有放弃当前的方案,还是直接使用真实值作为标签进行训练。
在将真实值作为标签,并添加monthday等几个特征之后进行训练,最终得分如下:
1 | MSE: 75.0699 |
这个成绩要比我预期的好很多,通过下面这张预测值与均值曲线的对比可以发现,预测值总体趋势和均值相当且比较接近,但是预测值的变化趋势一直在抖动,不够稳定平滑,这样的话评分标准中趋势变化40分那部分得分相较上一个版本就会有所损失。
2020.05.04
v0.0.6 版本:67.5497
只是将模型更换为了XGBoost,别的特征啥都没改变,模型参数也是随便抄的,还没调参。之后主要准备使用XGBoost来进行训练了。
1 | MSE: 60.3694 |
v0.0.7 版本:70.9289
通过对数据集的观察,发现之前选取的区间还不够好,于是重新调整数据范围如下:
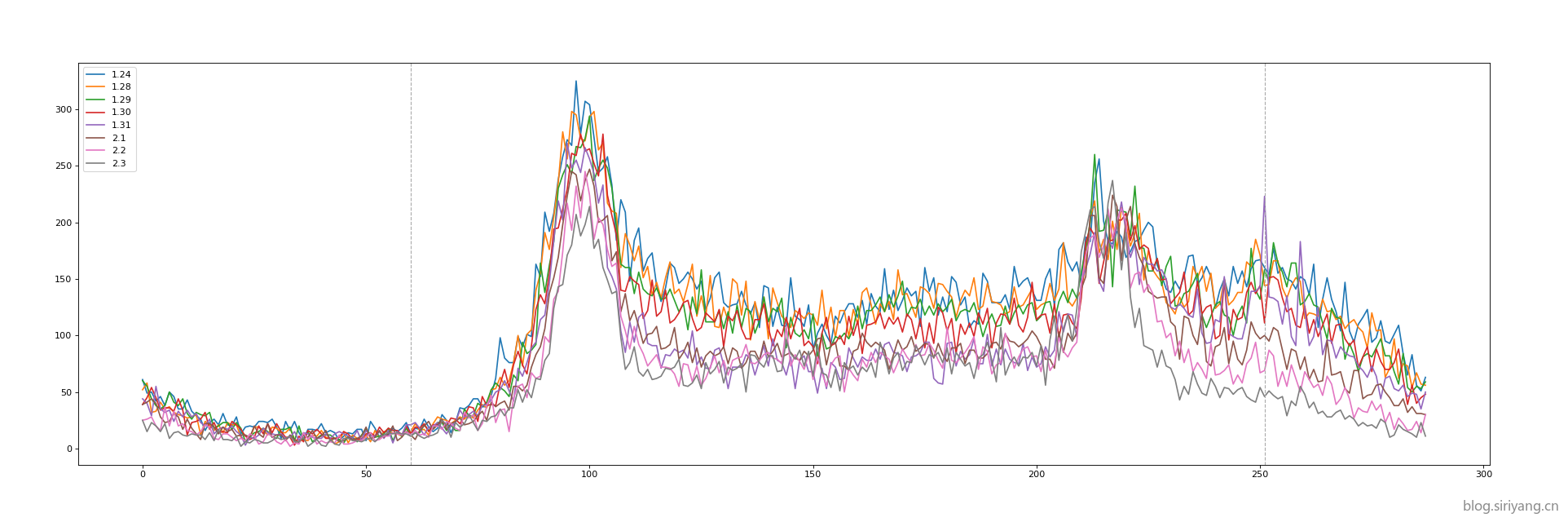
并且由于我们只是预测5:00到21:00范围内的流量,而我们数据集包括了0:00到24:00的数据,于是我将5:00~21:00以外的数据抛弃,仅针对该区间范围进行训练。由于我们加入了周末的数据,所以额外添加一个is_weekend特征,虽然从数据上看重要性很低,但是该特征的有无对MSE的影响比较大,这一点上也符合我对数据集的观察。
1 | MSE: 14.3629 |
2020.05.05
今天做了很多尝试,在特征提取之前先将数据集进行划分,然后再分别提取特征。因为之前的特征提取方法有点问题,测试集的历史特征也被提取到训练集中去了,现在我单独拿出一整天的时间作为测试集。同时我还实现了线上评分标准的计算公式,以便能更好的观察当前模型的不足。最后我还加入了之前爬取的天气特征。
做完上述工作以后我发现我的模型还是存在一个很大的问题————严重过拟合。出现问题的原因有下:
- 将测试集的特征也提取到了训练集中。
- 训练数据较少,迭代次数过多。
- 这点很关键,因为调整数据集以后,每个曜日的数据只有一天,每个曜日同时间索引的值只有一个,这样在提取
number_weekday_timeindex_...系列特征的时候对于max、min、mean、median这几个参数的取值完完全全就等于number,而std、var、cov这些值又没法进行计算,所以结果为NaN,最后被我填充为了0。我当时还奇怪了好久,怎特征还提取出空值来了。所以这样说来我完全是把标签作为特征在进行训练,难怪那几个值的重要性那么高,训练出来的MSE也低得惊人。当我把训练集部分的数据按整天进行预测再可视化对比于后,预测曲线和真实值几乎一模一样,当再去预测训练集之外的时间时泛化能力就严重不足。
所以说之前搞了半天一直都是走在一条错误的道路上,接下来我都会将数据集提前进行划分再提取特征,对于number_weekday_timeindex_...系列特征目前数据集上无法提取,只有抛弃不用了。
2020.05.22
v0.1.10 版本:75.7266
距离上一次更新已经半个多月了,从版本号和分数上也能看得出来做了很多迭代和尝试,因为忙于考研复试就一直没有更新博文。
我将第二位版本号从0变为1是因为在这个大版本下我将之前的单模型预测改为了双模型,使用两个模型来分别预测11日数据和14日数据。经过与大佬交流学习和个人分析认为,节前与节后是程一个镜像对称的趋势,当然不会是完全对称。从数据集可以看出越临近春节,流量曲线的总体水平就越低,这是因为很多人已经提前离开回家过年去了。而年后返工上班的话,流量则应该是会越来越多,并且按照我们的生活经验,节后返工的速度要比节前回家更快。所以由此我们可以推断出14号流量应该比11号更高,甚至14号可能已经完全恢复了正常的工作状态。其实从JerryX大佬一篇关于华为另一个数据竞赛的数据分析文章也可以看出,在距离五和张衡路口不远处的深圳北站,14号交通拥堵情况明显高于11号,且晚高峰有位突出,想必五和张衡路口的交通流量也会有类似的趋势。
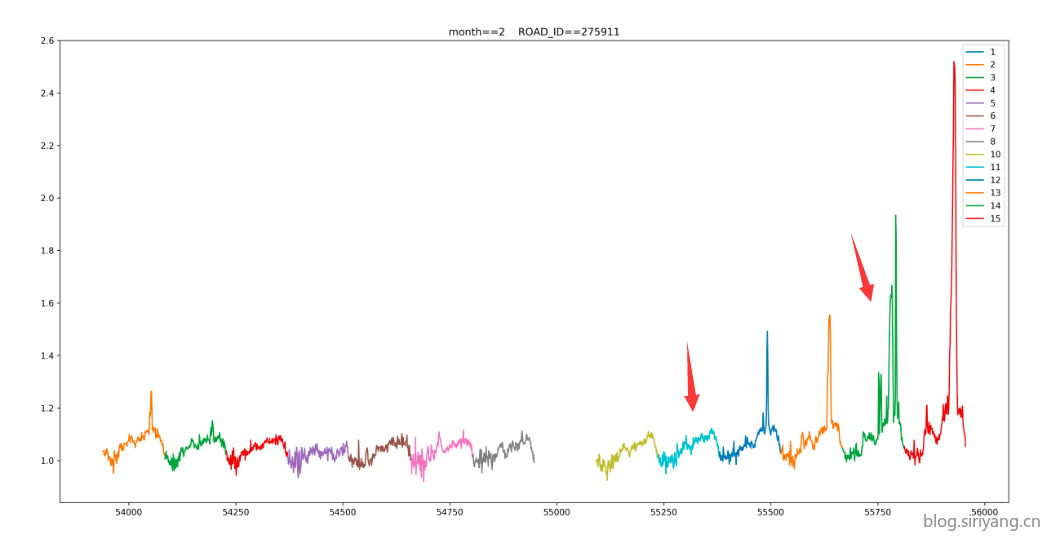
但在我之前的版本中,预测出来的结果与我设想是完全相反的,11号流量反而比14号更高。经分析,导致这个现象的原因是weekday特征。该特征的存在会导致我们的模型学习到一个周期循环的趋势,因而对应节前一周流量越来越低的趋势,11号预测流量会比14号更高。为了解决这个问题,我首先在训练时去除了weekday特征,取而代之的是一个days_to_holiday,该特征代表当天距离春节假期的天数。在这个特征加入以后,模型14号的预测结果确实比11号更高了,但是也并没有高多少,提交结果也还是60多。
于是我参考大佬的经验策略,直接针对这两天训练两个模型分别进行预测。对于11号取1.30–2.3的数据作为训练集,14号取1.28–2.1的数据作为训练集。训练出来以后再分别对11号和14号进行预测,然后整合数据。最后得到的预测结果发现14号要明显高于11号,符合我的预期。在训练过程中我去除了所有天气特征,感觉用处不大,在我们训练集范围内的气温几乎比较稳定,天气也都是阴天为主,也就14号下雨。最后模仿大佬的经验,针对训练集每一天21:00前趋势走向是上升还是下降手工标注一个是否加班的特征(work_overtime)。当然,导致夜间流量上升的不一定都是加班,还有可能是一些深夜栏目,比如14号情人节😎。在此我将11、14号都标记为加班。数据预测出来后,我还对结果数据做了一个微微的拉伸,因为我觉得实际流量应该比我的预测值更高,线上成绩也确实有所提升。之后的话考虑将训练集的时间窗口向前滑动,取更远离节日的数据进行训练。
而在模型提交上,我觉得华为云平台实现双模型有点麻烦,于是就在baseline代码的基础上进行修改,在线下代码中直接完成数据预测并保存到json文件,然后将保存的结果文件和模型文件一同提交部署,最后在推理代码的后处理部分读取并提交成绩。
最后推荐一下我队长的博文,我很多经验都是从他那学的:2020华为云大数据挑战赛之热身赛(持续更新)
热身赛最后在队长的带领下拿下第一,正式赛再接再厉!😀
![]()
这个是一等奖的奖品,一块原价699的荣耀魔法手表!


