赛题分析及数据观察
我们的数据集是从2019年1月12日到2019年2月8日。要预测的数据是2019年2月11日和2019年2月14日,分别是春节放假结束的第一天和情人节。
原始数据格式如下:
| time | cross | direction | leftFlow | straightFlow |
|---|---|---|---|---|
| 2019/1/12 00:00:00 | wuhe_zhangheng | east | 3 | 8 |
| 2019/1/12 00:05:00 | wuhe_zhangheng | east | 1 | 8 |
总计865600条数据。
包括六个路口:
'wuhe_jiaxian':五和路-稼先路'chongzhi_jiaxian':冲之大道-稼先路'wuhe_longping':五和路-隆平路'chongzhi_longping':冲之大道-隆平路'wuhe_zhangheng':五和路-张衡路'chongzhi_beier':冲之大道-贝尔路
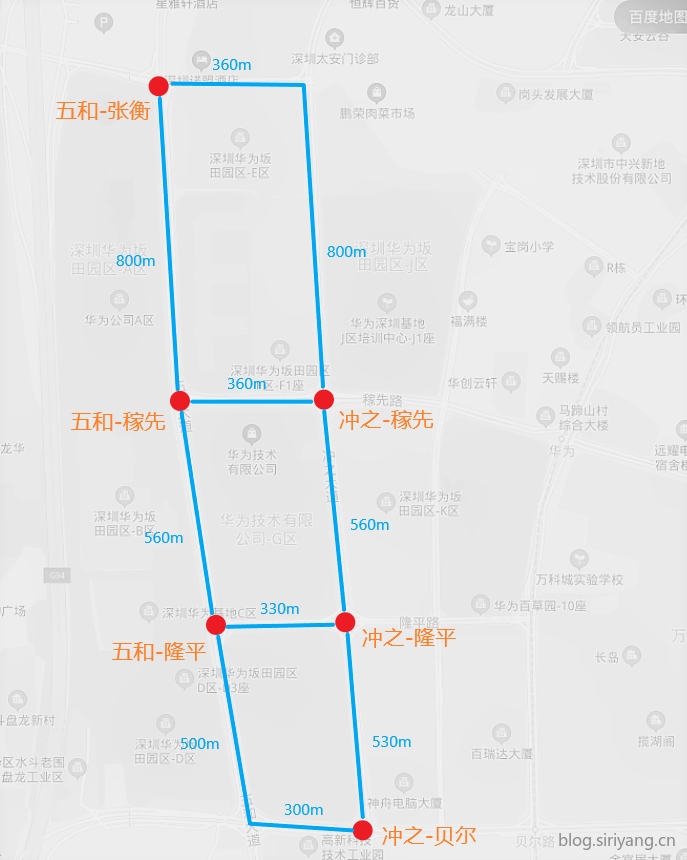
将五和张衡路口的四个方向流量总和数据可视化:
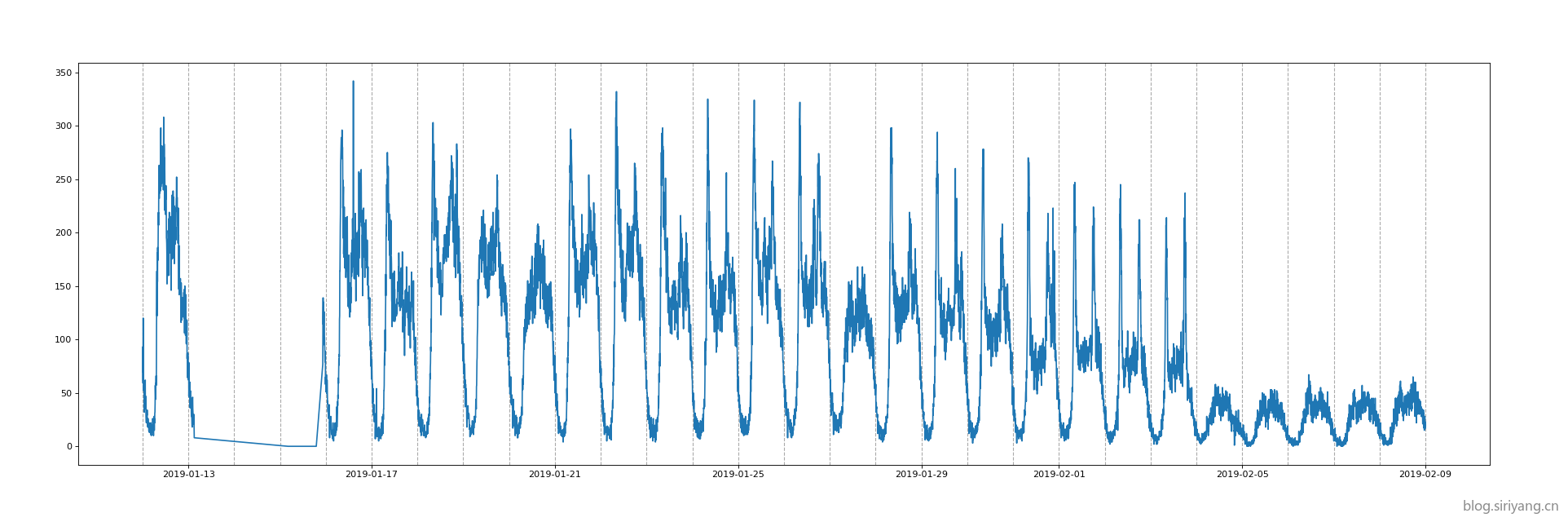
可见数据有明显的周期性(以天为周期),其中1月有长达两天半的缺失值。在2月4日开始进入春节假期,车流量明显减少。
参考资料:
- 2020中国高校计算机大赛·华为云大数据挑战赛-热身赛
- 2020中国高校计算机大赛·华为云大数据挑战赛热身赛——交通流量预测赛题分析4.19更新版(持续更新!!!)
- 2020中国高校计算机大赛·华为云大数据挑战赛热身赛–EDA
获取天气数据
通过天气网站获取深圳2019年1月和2月的天气:
1 | 日期,白天天气,夜间天气,白天气温,夜间气温,白天风向,白天风级,夜间风向,夜间风级 |
参考资料:
Baseline
baseline代码分析:
1 | import moxing as mox |
输出结果:
1 | Copy procedure is completed ! |
线上提交成绩:35.6483
该baseline仅使用了五和张衡路口的交通流量数据,并提取了'weekday','timeindex'两个特征进行训练。在预处理过程中对数据范围做了归一化压缩。
从题目可知是要预测路口四个方向车流量之和,然而baseline使用的单个方向的均值作为标签,直接将聚合函数由mean改为sum即可获得64.8分。
customize_service
由于我们提交给服务器的只是训练好的模型,还要对数据做预处理和识别结果后处理,这些操作在与模型文件一同提交的customize_service.py文件中执行。
1 | # -*- coding: utf-8 -*- |

