2020.08.12
词袋模型
原理
词袋模型是一种用机器学习算法对文本进行建模时表示文本数据的方法。词袋模型假设我们不考虑文本中词与词之间的上下文关系,仅仅只考虑所有词的权重。而权重与词在文本中出现的频率有关。
词袋模型首先会进行分词,在分词之后,通过统计每个词在文本中出现的次数,之后可以得到该文本基于词的特征,将各个文本样本的这些词与对应的词频放在一起,这也就是用词向量表示这个文本。向量化完毕后一般也会使用 TF-IDF 进行特征的权重修正,再将特征进行标准化。 再进行一些其他的特征工程后,就可以将数据带入机器学习算法进行分类、聚类了。
词袋模型有多种,最常用的是 BOW(Bag of Words)和 One-hot 表示。
优缺点
词袋模型的三部曲分别是分词(tokenizing),统计词特征值(counting)与标准化(normalizing)。
词袋模型中最重要的是构造词表,然后通过文本为词表中的词赋值,但词袋模型严重缺乏相似词之间的表达。比如“我喜欢重庆”“我不喜欢重庆”其实这两个文本是严重不相似的。但词袋模型会判为高度相似。“我喜欢重庆”与“我爱重庆”其实表达的意思是非常接近的,但词袋模型不能表示“喜欢”和“爱”之间严重的相似关系。
TF-IDF
原理
TF-IDF 是一种统计方法,用以评估某个单词对于一个语料库中某篇文章的重要程度。
该方法由两部分组成:
- TF(Term Frequency)为词频,表示单词(非停用词)在文章中出现的频率,在公式中,使用文章总次数进行归一化,防止同样的词频在长文本和短文本中差异较小。
- IDF(Inverse Document Frequency)为逆文档频率,在词频的基础上,赋予每个单词一个权重。如果某个单词在某篇文章中多次出现(TF 值较大),而在整个语料库中较少出现(IDF值较大),则该单词可以视为该篇文章的关键词,反之,如果某个单词在某篇文章中出现多次(TF 值较大),而在整个语料库中也出现多次(IDF 值较小),则该单词可以视为整个语料库的常用词,在该文章中重要度不高。公式如下所示:
$$TF=\frac{某个单词在文章中出现的次数}{文章的总词数}$$
$$IDF=\log(\frac{语料库的文章总数}{包含该词的文档数+1})$$
$$TF\textrm{-}IDF=TF*IDF$$
TF-IDF 的值即为 TF 与 IDF 的乘积,从公式可以看出,某个单词的重要性(TF-IDF)与它在文章中出现的次数成正比,与它在整个语料库中出现的频率成反比。
优缺点
TF-IDF 算法虽然实现简单快速,但仍存在很多缺点:
- 没有体现单词的位置信息,在提取关键词时,位于标题、首句或尾句的单词可能包含较重要的信息,应该赋予较高的权重。
- 从公式可以看出,TF-IDF 倾向于文本频率较小的单词,故一些生僻词会因为 IDF值较高被误认为文章的关键词,相反,一些常用词可能 TF-IDF 值较小,但并不代表它对文章不重要,例如一些公众人物、热点事件等。
- 严重依赖语料库,需要选取质量较高且和所处理文章相符的语料库进行训练,例如所处理文章为 2019 年的新闻,而训练 TF-IDF 的语料为 2016 年的新闻集,此时,新闻的时效性就会影响关键词的选取。
- 只考虑了单词与它所出现的文章数量之间的关系,而忽略了单词在不同类别间的分布情况,例如,单词“大数据”在计算机类相关文章出现次数较多,但这会被 TF-IDF 认为是常用词,而非关键词,此时应该统计“大数据”一词在不同类别语料中出现的次数,从而赋予在计算机相关文章中的“大数据”一词更高的权重,使得其被认定为关键词。
词向量模型
NNLM(Neural Network Language Model)
NNLM 的本质是从语言模型出发,将模型最优化过程转换为求词向量表示的过程,目标函数如下所示:
$$L(\theta)=\sum_t \log P(W_t | W_{t-n+1},\cdots ,W_{t-1})$$
$$s.t. \sum_{w\in { vocabulary }} P(W_t | W_{t-n+1},\cdots ,W_{t-1})=1$$
其中,t 为语料库中所有曾出现在$W_{t-n+1},\cdots ,W_{t-1}$这 n-1 个词后面的单词的下标,NNLM的目的就是最大化目标函数值。概率 p 需要满足归一化条件,如第二个公式所示,这样不同位置 t 的概率才能相加。
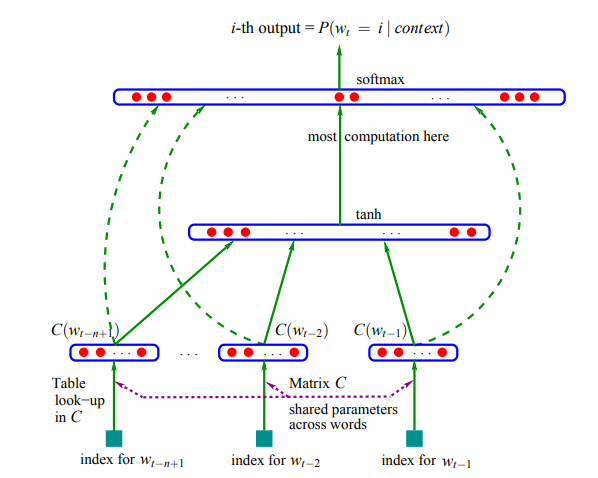
上图为 NNLM 的整体架构图,由投影层,隐藏层和输出层三部分组成,作用分别为:①假设字典中包含 V 个单词,目标是获得 D 维的词向量,如上图所示,$index; for; W_{t-n+1}$为一个 V 维的 one-hot 编码,其中 $W_{t-n+1}$ 在字典中的下标为 idx,则在 V 维向量中下标为 idx的值为 1,其余值为 0;此外,C 矩阵为投影矩阵,也是最后获得的词向量矩阵,如下所示:
$$C=(W_1,W_2,\cdots,W_v)=\left[ \begin{array}{cc}
(W_1)_1 & (W_2)_1 & \cdots & (W_v)_1 \\
(W_1)_2 & (W_2)_2 & \cdots & (W_v)_2 \\
\vdots & \vdots & \ddots & (W_v)_1 \\
(W_1)_D & (W_2)_D & \cdots & (W_v)_D \\
\end{array} \right]$$
投影矩阵维度为 D 行(词向量维度)× V 列(字典中单词个数),故矩阵中第 i 列为字典中第 i 个单词的词向量,投影层的目的就是通过矩阵乘法选取$W_{t-n+1},\cdots ,W_{t-1}$这 n-1 个词的词向量,并将它们拼接成个 1×(n-1)*D 的向量;②在隐藏层中,将投影层输出的向量作为输入,送入一个激活函数为 tanh 的全连接层进行处理,输出结果为一个 1×H 的向量;③输出层为一个 softmax 分类器,即一个激活函数为 softmax 的全连接层,预测词典中每一个单词出现的概率,故输出层的输出结果为一个 1×V 的概率向量。根据输出结果和真实结果计算损失函数的值,再利用梯度上升法和反向传播等技术更新网络中的参数,先前初始化的矩阵 C 随着模型训练结束就成为了词向量矩阵。
word2vec: CBOW
由于 NNLM 的计算复杂度为(n-1)*D(输入层-> 投影层)+ (n-1) *D *H(投影层-> 隐藏层) + H *V(隐藏层-> 输出层),而且想要训练出一个表现良好的 NNLM 需要大量的数据集,所以 NNML 对计算资源要求很高。Google 对 NNLM 进行了改进并推出了 word2vec:CBOW 模型,改进如下:
- 使用前后 n 个单词去推断中间词。
- 在 NNML 的投影层中,词向量是横向拼接,这使得向量维度过大,从而导致隐藏层的参数过多,在 word2vec 的投影层中,将 n 个单词的词向量相加作为输出,降低了向量维度,减少了后续层的参数,提高了训练速度。
- 去掉隐藏层,使投影层直接与输出层相连,大大减少了参数数量,加快了计算速度。
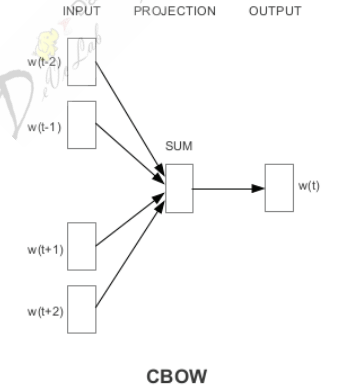
- 在输出层,不再使用 softmax 分类器(假设字典中单词数量为 100 万,词向量维度为 500 维,此时 softmax 分类器参数量约为 5 亿,训练代价过大),而是使用 Hierarchical softmax 策略对输出层进行优化,使得输出层从原始模型的利用softmax 计算概率值改为利用 Huffman Tree 来计算概率,其中以字典中所有单词作为叶子节点,词频作为节点权重来构建 Huffman Tree。word2vec: CBOW 的整体结构如下图所示
word2vec: Skip-Gram
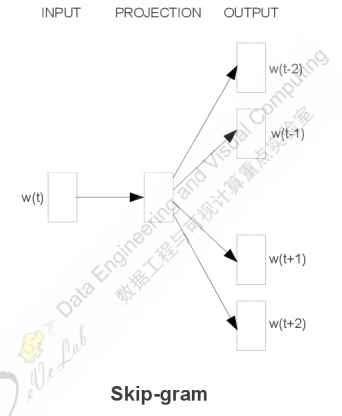
上图所示为 word2vec 的另一种实现方案,即使用中心词预测上下文单词,此时$X_\omega$为中心词的词向量。在 Skip-Gram 方案中,目标函数为$L=\frac{1}{T}\sum_{t=1}^T \sum_{-c\le j\le c,j\ne 0} \log (P(\omega_{t+j}|\omega_t))$,其中 T 为中心词个数,c 为窗口大小。skip-gram 方案同样可以在输出层使用 Hierarchicalsoftmax 和 Negative Sampling 这两种加速策略,只不过在 Hierarchical softmax 中,每一个非叶子节点需要为每一个要预测的上下文单词初始化一个参数向量,在 Negative Sampling 中,需要为每一个要预测的上下文单词进行一次负样本采样,此时,针对每一个上下文单词的预测,参数更新与 CBOW 方案一致。
word2vec 的优缺点
优点:
- word2vec 会考虑窗口内的上下文信息,比 one-hot 编码等方式效果好。
- 可以自定义词向量维度,训练速度快。
- 通用性很强,适用于各种 NLP 任务。
缺点:
- 词和向量是一对一关系,所以多义词的问题无法解决,比如“我爱吃苹果”和“我爱用苹果手机”这两句中的“苹果”在 word2vec 使用相同的词向量表示,显然这是不合适的
- word2vec 是一种静态的方式,虽然有很强的通用性,但却无法针对特定任务进行优化。
扩展内容
除了 word2vec,常用的词向量技术还有 FastText、Glove 和 Elmo 等,它们各有各的优缺点,要结合使用应用场景,灵活选择词向量技术。此外,还可以通过训练多个词向量模型,将不同模型的词向量进行拼接,送入神经网络模型中,例如训练 word2vec、FastText和 Glove 这三个词向量模型(各 100 维),将它们对“苹果”一词的词向量进行横向拼接,变成 300 维的词向量送入模型中。

