本文承接个人数据中心解决方案,实现系统架构中的数据采集模块,详细讲解数据的采集以及调度方案。
数据采集项目结构
1 | data_acquisition |
上面是我数据采集项目data_acquisition文件夹下的目录结构,包含了分别从Notion以及LeadCloud上采集数据的py脚本以及crontab定时调度的sh脚本。
调度系统的设计方案之前在个人数据中心解决方案一文中已经初步阐述。
我们需要做的就是在本地开发主机上创建该文件夹进行项目开发,然后参照下面这篇文章的方案将项目推送到远程服务器的指定文件夹进行部署:推送项目到远程仓库并触发执行sh脚本
数据采集脚本
由于第三方数据服务中Notion数据库的使用占比较高,本文将以Notion数据表中的书单表采集脚本实现为例,其他数据源可按照类似的框架进行实现。
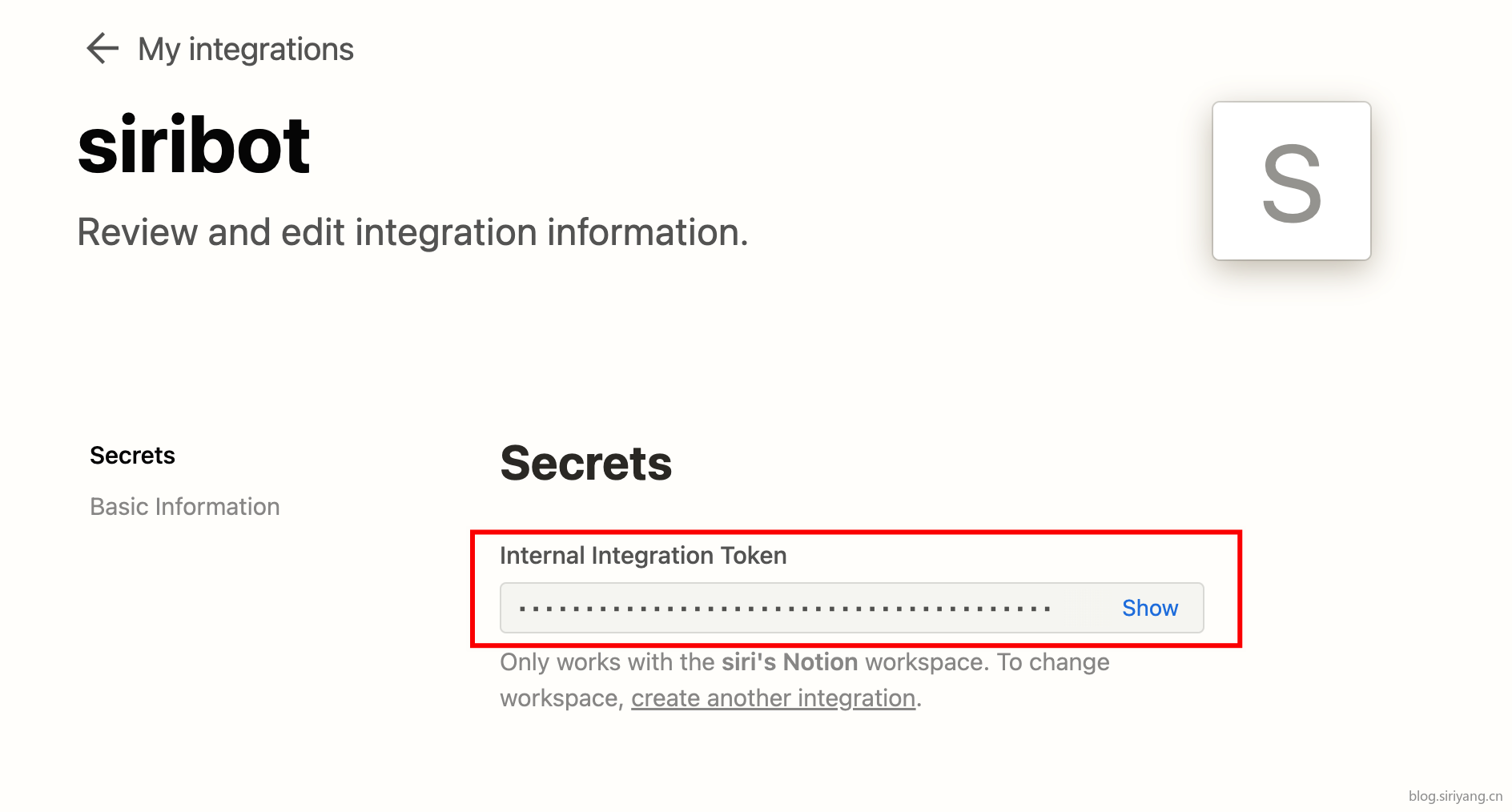
要是用Notion API首先需要创建一个机器人:https://www.notion.so/my-integrations

点击创建好的机器人可以看到他的一些详细信息,其中token是我们之后需要用到的。你也可以在该页面配置机器人的各种权限。
然后将创建好的机器人配置到你想要采集的数据表上,这样它才有该表的读写权限。

参照Notion API官方文档上的案例即可开始编程:https://developers.notion.com/reference/intro
由于Notion API返回到都是json字符串,需要进行复杂的数据解析。为了简化从Notion中采集数据的代码,我将一些可复用的代码进行封装,统一放在NotionAPI.py里。如下所示,分别实现了全表的获取以及个类型数据解析的函数:
1 | import requests |
基于上面的工具函数,我们在接下来的开发过程中就能简化很多代码。
由于Notion中的数据格式与MySQL的数据格式不同,这里需要进行数据格式的转换:
| 字段名 | Notion数据类型 | MySQL数据类型 | 备注 |
|---|---|---|---|
| id | 文本 | String | 页面id |
| book_name | 标题 | String | 书名 |
| auther_name | 文本 | String | 作者名 |
| auther_country | 文本 | String | 作者国籍 |
| book_type | 多选 | String | 图书类型 |
| book_price | 数字 | Float | 图书价格 |
| book_patform | 多选 | String | 阅读平台 |
| read_datetime_start | 日期 | DateTime | 阅读开始时间 |
| read_datetime_end | 日期 | DateTime | 阅读结束时间 |
| book_page_readed | 数字 | Float | 已读页数 |
| book_page_all | 数字 | Float | 总页数 |
| status | 单选 | String | 阅读状态 |
由于我们是采用全量同步的方式进行采集,所以我选择使用pandas的接口来进行向MySQL的整表数据覆写,每次调用会将之前的数据表删掉,然后基于新的数据创建一张新表。
1 | import requests |
定时调度脚本
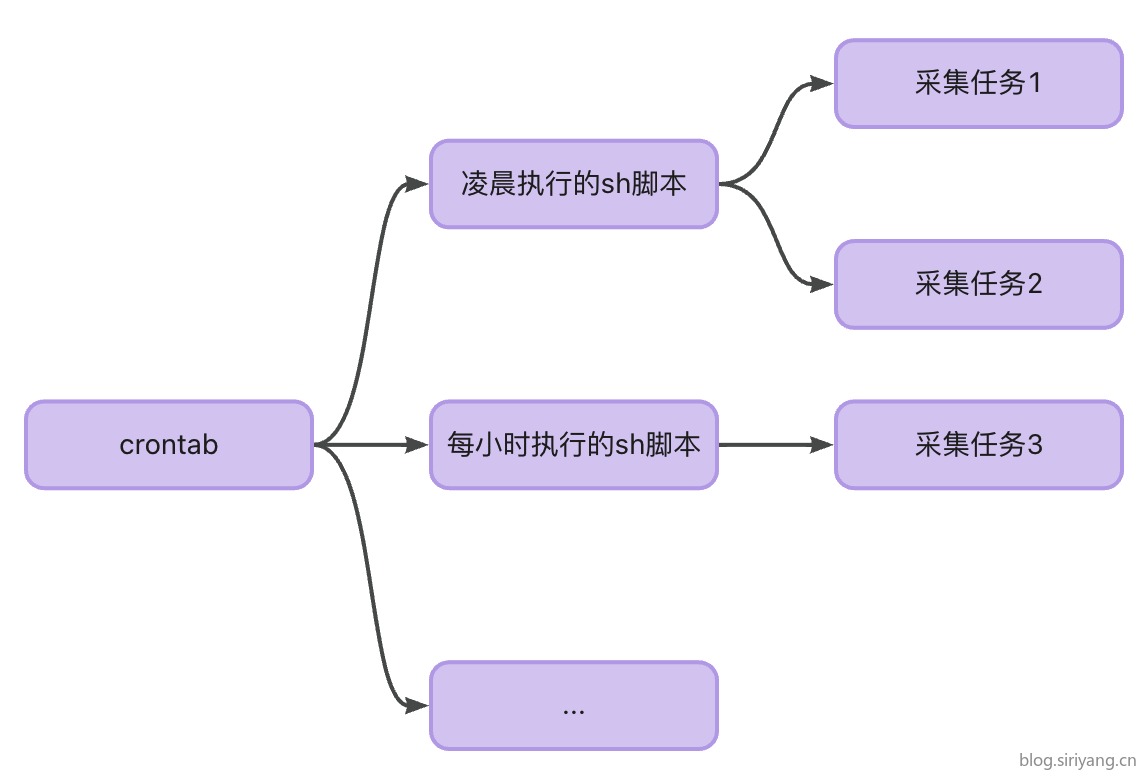
首先我们在本地项目中编写好每日零点执行的sh脚本,在该脚本中制定一个或多个我们要执行的采集任务脚本:
1 | # 0 0 * * * |
以后所有在零点执行的任务都可以写在上面这个sh脚本中。在一个脚本中执行多个任务的时候注意异常处理,否在中间的任务失败可能会导致后面的任务全部中断执行。
在这里我还为环境变量加上一个编号使其与其他同样零点执行的脚本中的变量区分开,防止发生干扰,产生意料之外的结果。
接下来在远程服务器端进行crontab命令配置。crontab是Linux系统通常会默认自带的一个工具,可以直接使用。
打开crontab命令编辑界面:
1 | crontab -e |
这其实就是一个vim编辑界面,使用vim的操作指令进行输入保存和推出。
具体写入内容如下:
1 | 0 0 * * * sh /your_path/data_acquisition/crontab_daily_report.sh # 每日播报脚本 |
上面我编写了三条定时任务命令,分别是在每天零点执行的播报任务和数据采集任务,以及每小时的58分执行一次的数据采集任务。
该命令配置好以后,只要我们调度的时间不变,剩下的开发我们就只需在本地项目中进行文件修改和远程推送部署,不需要再连接远程服务器进行任务配置。
至此,整个数据采集系统就完成了,该系统不仅仅能进行数据采集,还能执行数据播报以及数据备份等更多定时调度任务。
使用腾讯云函数进行任务部署及调度的方案请参照这篇文章
相关代码已托管于GitHub,欢迎Star!

