前言
首先测试下环境是否安装成功:
1 | import xgboost as xgb |
没想到第一步就出了问题,一开始安装的numpy 1.13.1在运行时找不到DLL,升级到1.14.1就好了。
正文
今天来完成任务一的前三个实验,都是基于**课后作业(二)**的,位于实验指导书的P55页。
实验一
实验题目及内容:
用Python实现F1-score,并自己构建一个简易数据集进行测试
实验过程步骤:
F1-score的概念在P25页。
| 真实情况 | 预测:正例 | 预测:反例 |
|---|---|---|
| 正例 | TP(真正例) | FN(假反例) |
| 反例 | FP(假正例) | TN(真反例) |
查准率P(Precision):
$$P=\frac{TP}{TP+FP}$$
查全率R(Recall):
$$R=\frac{TP}{TP+FN}$$
F1-score定义:
$$F1=\frac{2PR}{P+R}=\frac{2TP}{TP+FN+FP}$$
数据集我准备使用随机函数生成类似实验报告癌症预测的数据。
1 | import numpy as np |
输出:
1 | 1_白细胞量 2_红细胞量 3_血小板量 4_是否患癌 5_预测标签 |
2020.2.4更新
0117第一次评测:
掌握了F1-score的定义,并使用代码实现;数据集规模太小。
按照1月17号提交结果的评测来看需要加大数据集。
实验二
实验题目及内容:
用
python中的for循环和列表推导式,分别实现计算:1+2+3+…+1000
实验过程步骤:
这个实验比较简单,几行代码就搞定了。
1 | # for 循环 |
运行结果:
1 | for 循环: 500500 |
不过要注意的是,如果第一个变量s取名为sum,那么下面再调用sum函数的时候就会产生歧义而导致报错。
实验三
实验题目及内容:
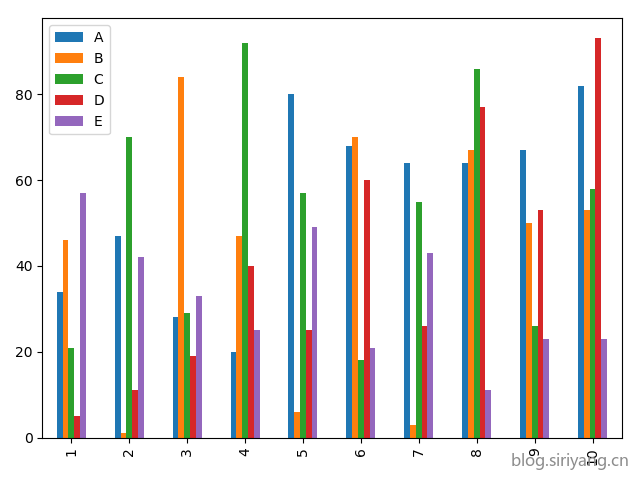
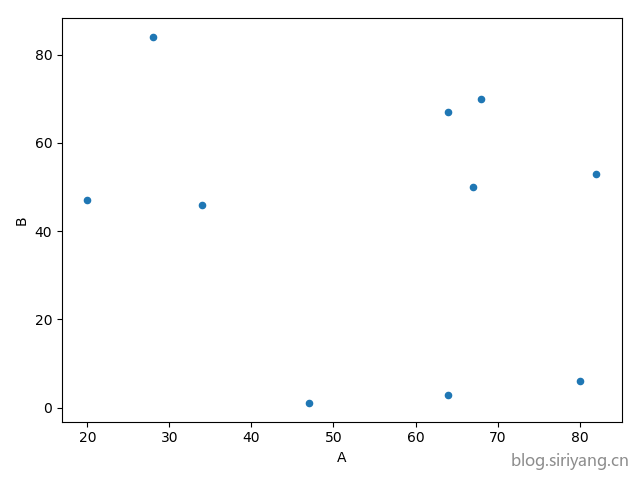
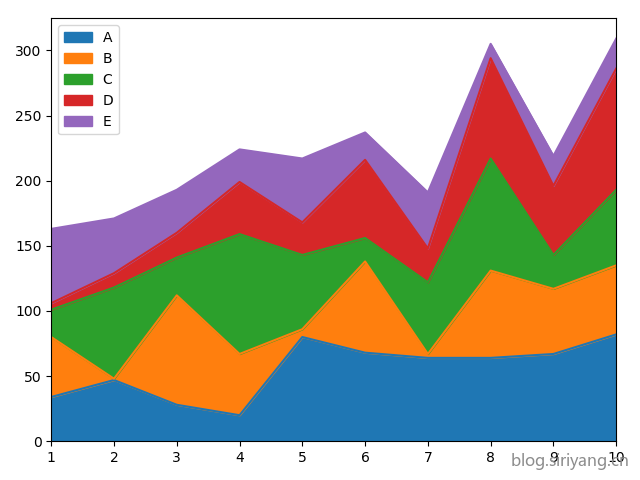
随机生成一个五列十行的
dataframe的数据类型,行列索引自定义,绘制出对应的柱状图、散点图,以及在查询官网学习绘制一个课程未讲解(即除柱状图、饼图、散点图、箱线图以外的图形)的数据分析的图形
实验过程步骤:
正好继续使用第一个实验的数据集,然后随便取两个字段来绘制图形。
1 | import numpy as np |
输出数据:
1 | A B C D E |
绘制图形: