前言
KMeans算法本身说起来还算简单,但具体实现起来还是不容易啊。
正文
今天来完成任务一的实验四:实现Kmeans算法,并测试5个数据集。
代码
要导入的包有:
1 | import numpy as np |
工具函数
懒得去找数据集了,还是使用随机数生成:
1 | if __name__ == "__main__": |
接下来的两个函数在之后的寻找K和计算聚类都会用到。
根据数据集和选取的K值随机生成k个初始点:
1 | def randCent(dataMat, k): |
计算欧式距离:
1 | def distEclud(vecA, vecB): |
findBestK
首先确定该数据集K的最佳取值:
1 | def cost(dataMat, k, distMeas=distEclud, createCent=randCent,iterNum=300): |
KMeans
最后选取一个较好的聚类结果:
1 | def kMeans(dataMat, k, distMeas=distEclud, createCent=randCent): |
实验结果及数据
随机生成的数据终究效果不怎么好,最后还是去网上找了两个样例数据来试试(真香)。
数据1
findeBestK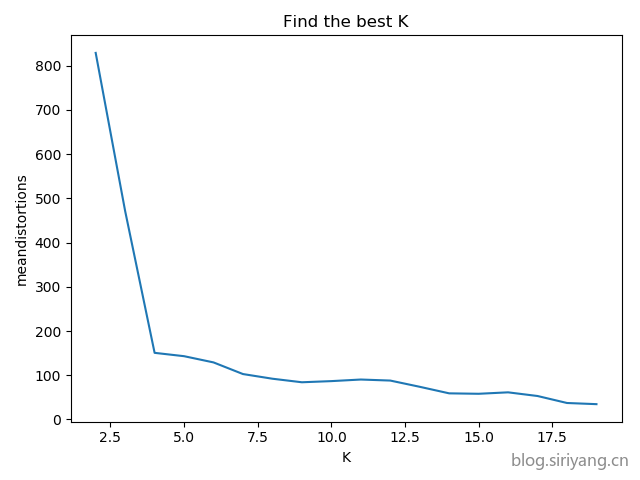
KMeans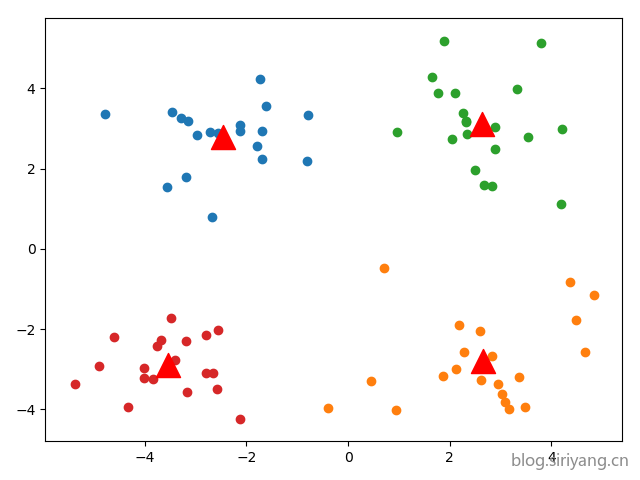
数据
1 | X,Y |
数据2
数据
findeBestK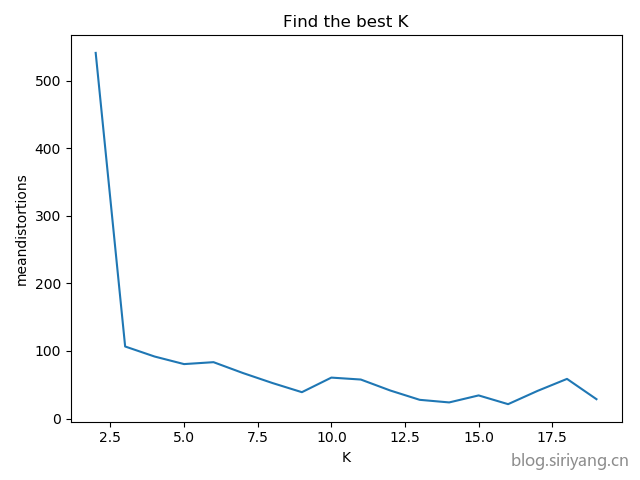
KMeans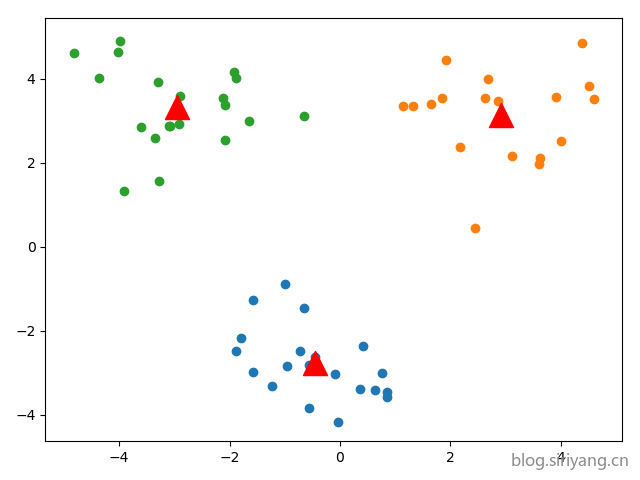
1 | 3.275154,2.957587 |
2020.2.4更新
0117第一次评测:
代码实现了Kmeans算法,并进行了算法优缺点分析以及对5个数据集的算法测试,采用了手肘法选出了每个数据集的最优K值。
按照1月17号提交结果的评测来看需要进行算法优缺点分析。
算法分析:
优点:Kmenans算法是最基础的无监督聚类算法,原理简单,实现容易。
缺点:
- 收敛较慢
- 算法时间复杂度比较高 O(nkt)
- 不能发现非凸形状的簇
- 需要事先确定超参数K
- 对噪声和离群点敏感
- 结果不一定是全局最优,只能保证局部最优
结语
网上KMeans的博客教程非常多,但代码多多少少都有点问题。这个代码算是比较好的了,注释非常详细,但一开始还是有个bug,调了老半天才弄好。就是在求欧式距离那个函数里,原来使用的求和函数是sum,但是用这个求和函数计算numpy矩阵算不出来,导致后面一直报错,最后换成numpy.sum就OK了。
还有一个问题就是原作者一开始使用的是手动读取分割文本数据,我直接调用的pandas函数,导致读进来的数据格式有点不一样,也跑不成。后来调试发现他把数据都转成了numpy矩阵,而我用的是list矩阵,之后手动转换一下就解决了。
感觉做机器学习这些最麻烦的就是数据格式的处理,尤其是不能把numpy和list随便混用,不然后面多半要翻车。不过随着不断练习,数据处理经验逐渐丰富,越往后做起来会更得心应手一些。

