Bagging vs Boosting
共同点:
Bagging和Boosting都是集成模型,都是由很多个弱分类器(base/weak learners)构成的。
不同点:
Bagging:由过拟合的弱分类器集成。Boosting:由欠拟合的弱分类器集成。
提升树
提升树——基于残差的训练。
残差——真实值减去预测值的差值。
$$最终预测=模型1的预测+模型2的预测+模型3的预测\dots$$
XGBoost
算法优点:
- 算法可以并行、训练效率高
- 比起其他的算法,实际效果好
- 由于可控参数多,可以灵活调整
如何构造目标函数?
目标函数非连续型,难以优化,使用近似的方法。目标函数直接优化难,如何近似?
使用泰勒展开近似目标函数。如何把树的结构引入到目标函数?
仍然难优化,要不要使用贪心算法?
构造目标函数
使用多棵树来预测
假设已经训练了K颗树,则对于第i个样本的(最终) 预测值为所有树权值之和:
$$\widehat{y_i}=\sum_{k=1}^{K} f_k(x_i),f_k\in \mathcal{F}$$
目标函数的构建
$$Obj=\sum_{i=1}^n l(y_i,\widehat{y_i})+\sum_{k=1}^K \Omega(f_k)$$
- $\sum_{i=1}^n l(y_i,\widehat{y_i})$:损失函数
- $\sum_{k=1}^K \Omega(f_k)$:正则项
- $\Omega(f_k)$:第k棵树的复杂度
树的复杂度
- 叶节点个数
- 树的深度
- 叶节点值:将叶节点的值限制的越小,树的复杂度降低,要达到目标结果就需要更多的树进行累加
- …
叠加式的训练(Additive Training)
已训练k-1棵树,现在要训练第k棵树:

给定:$x_i$
$\widehat{y_i}^{(0)}=0\longleftarrow$ Default Case
$\widehat{y_i}^{(1)}=f_1(x_i)=\widehat{y_i}^{(0)}+f_1(x_i)$
$\widehat{y_i}^{(2)}=f_1(x_i)+f_2(x_i)=\widehat{y_i}^{(2)}+f_2(x_i)$
$\vdots$
$\widehat{y_i}^{(k)}=f_1(x_i)+f_2(x_i)+\dots+f_k(x_i)$
$\ =\sum_{j=1}^{k-1}f_j{x_i}+f_k(x_i)=\widehat{y_i}^{(k)}+f_k(x_i)$
损失函数:$l(y_i,\widehat{y_i})$
目标函数:$Obj=\sum_{i=1}^n l(y_i,\widehat{y_i}^{(k)})+\sum_{j=1}^k\Omega(f_j)$
优化目标函数:$minimize Obj=\sum_{i=1}^n l(y_i,\widehat{y_i}^{(k-1)}+f_k(x_i))+\sum_{j=1}^{k-1}\Omega(f_j)+\Omega(f_k)$
当训练第k棵树时,仅需最小化:$\sum_{i=1}^n l(y_i,\widehat{y_i}^{(k-1)}+f_k(x_i))+\Omega(f_k)$
- $y_i$:真实值
- $\widehat{y_i}^{(k-1)}$:前
k-1棵树的预测值(constant) - $f_k(x_i)$:第
k棵树的预测值 - $\Omega(f_k)$:第
k棵树的复杂度
使用泰勒展开近似目标函数
使用近似的方法是为了把常数项抽取出来。
$Obj_k=\sum_{i=1}^n l(y_i,\widehat{y_i}^{(k-1)}+f_k(x_i))+\Omega(f_k)$
Taylor Expansion:$f(x+\Delta x)\approx f(x)+f’(x)\cdot\Delta x+\frac{1}{2}f’’(x)\cdot \Delta x^2$
令:
- $f(x)=l(y_i,\widehat{y_i}^{(k-1)})$
- $f(x+\Delta x)=l(y_i,\widehat{y_i}^{(k-1)}+f_k(x_i))$
所以:
$Obj_k=\sum_{i=1}^n l(y_i,\widehat{y_i}^{(k-1)}+f_k(x_i))+\Omega(f_k)$
$\ \,=\sum_{i=1}^n \left [ l(y_i,\widehat{y_i}^{(k-1)})+\partial_{\widehat{y_i}^{(k-1)}}\,l(y_i,\widehat{y_i}^{(k-1)})\cdot f_k(x_i)+\frac{1}{2}\partial_{\widehat{y_i}^{(k-1)}}^2 \,l(y_i,\widehat{y_i}^{(k-1)})\cdot f_k^2(x_i) \right ]+\Omega(f_k)$
$\ \,=\sum_{i=1}^n \left [ l(y_i,\widehat{y_i}^{(k-1)})+g_i f_k(x_i)+\frac{1}{2}h_i f_k^2(x_i) \right ]+\Omega(f_k)$
注:当训练第
k棵树时,{$h_i,g_i$}是已知的,$h_i$、$g_i$代表了前k-1棵树的残差。
新的目标函数
树的参数化
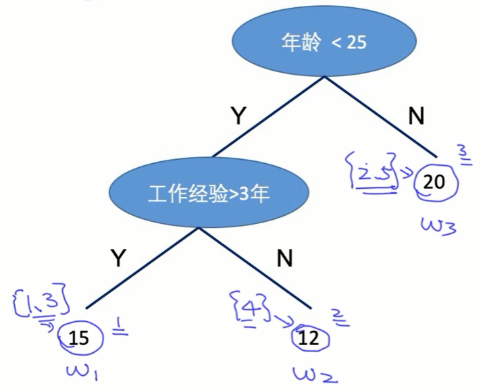
参数化:
$$f_k(x_i)=W_{q(x_i)}$$
- $W=(w_1,w_2,w_3)=(15,12,20)$:叶子权重向量
- $q(x);\ q(x_1)=1、q(x_2)=3、q(x_3)=1、q(x_4)=2、q(x_5)=3$:样本x的位置
- $I_j=\{j|q(x_i)=j\};\ I_1=\{1,3\}、I_2=\{4\}、I_3=\{2,5\}$:第j个节点里面有哪些样本。使用这种组织方式方便后面去掉参数下标
树的复杂度:
$$\Omega(f_k)=\gamma T+\frac{1}{2}\lambda\sum_{j=1}^T w_j^2+\dots$$
- $T$:叶节点个数
- $\sum_{j=1}^T w_j^2$:叶节点权值
- $\gamma、\lambda$:超参数(hyperparameter),用于控制模型对叶节点个数或权值的侧重。
新的目标函数
(假设树的形状已知的情况下)
$\sum_{i=1}^n \left [ g_i f_k(x_i)+\frac{1}{2}h_i f_k^2(x_i) \right ]+\Omega(f_k)$
$=\sum_{i=1}^n \left [ g_i\cdot W_{q(x_i)}+\frac{1}{2}h_i W_{q(x_i)}^2 \right ]+\gamma T+\frac{1}{2}\lambda\sum_{j=1}^T w_j^2$
按照样本去组织:$g_1\cdot W_{q(x_1)}+g_2\cdot W_{q(x_2)}+g_3\cdot W_{q(x_3)}+g_4\cdot W_{q(x_4)}+g_5\cdot W_{q(x_5)}$
按照叶节点组织:$\underline{g_1\cdot W_{q(x_1)}+g_3\cdot W_{q(x_3)}}+\underline{g_4\cdot W_{q(x_4)}}+\underline{g_2\cdot W_{q(x_2)}+g_5\cdot W_{q(x_5)}}$
$=\underline{g_1\cdot w_1+g_3\cdot w_1}+\underline{g_4\cdot w_2}+\underline{g_2\cdot w_3+g_5\cdot w_3}=\sum_{j=1}^3\sum_{i\in I_j} g_i\cdot w_j$
$minimize=\sum_{j=1}^T \left [ (\sum_{i\in I_j} g_i)\cdot w_j+\frac{1}{2}(\sum_{i\in I_j} h_i+\lambda)\cdot w_j^2 \right ]+\gamma T$
$G_j=(\sum_{i\in I_j} g_i)$与$H_j+\lambda=(\sum_{i\in I_j} h_i+\lambda)$均为常量,所以上式形似于$ax^2+bx+c$,所以有最优解$x^*=-\frac{b}{2a}$。
$w^*_j=-\frac{G_j}{H_j+\lambda}$
$Obj^*=-\frac{1}{2}\frac{G_j^2}{H_j+\lambda}+\gamma T$
在树的结构已知的情况下,我们能一下就计算出最优解。在树结构未知的情况下,我们的问题就是如何去寻找使目标函数最小的那个树。
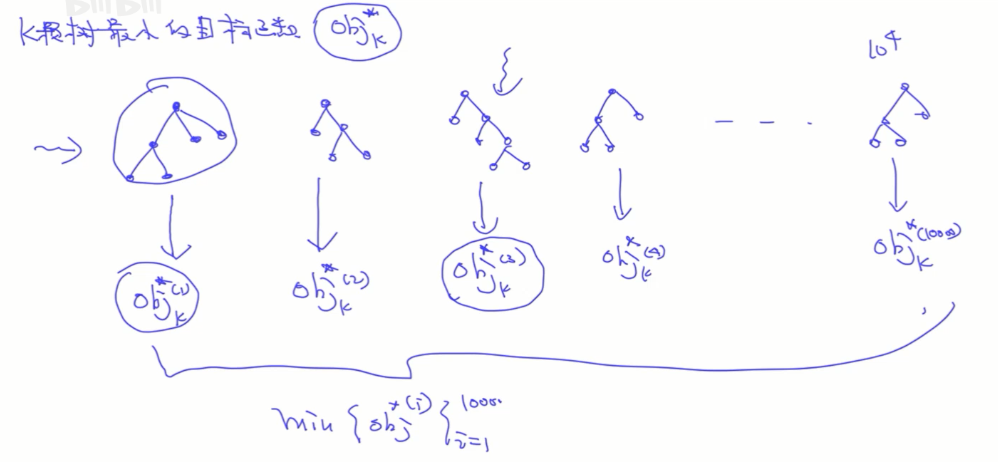
寻找最优的树的形状
如何寻找树的形状?
- 暴力搜索(Brute-Force Search),把所有形状的最小值都求一遍再比较。复杂度为$O(p^n)$,在资源有限的情况下,该方法不可能。
- 贪心的方法。
决策树:
在某一节点按某一特征做子节点的划分,之后子节点再按别的特征继续划分下去。
每次划分选择特征的标准是特征的score:原(不确定性)-之后(不确定性),称之为信息增益(Information Game),不确定性称为熵(Entropy),我们的目的就是要使信息增益最大。
XGBoost:
我们用决策树计算信息熵的方法来进行计算 $Obj$ 。我们在每次树分裂前后计算 $Obj_k^{*(old)}$ 和 $Obj_k^{*(new)}$ ,使两者的差值最大,每次分裂都采用最优的特征进行分裂。其实除了将信息熵替换为了 $Obj$ ,其他计算过程和决策树都是一样的。


