KNN概述
kNN(k-NearestNeighbor)算法是一种有监督的基本分类与回归方法,我们这里只讨论分类问题中的 kNN算法。
kNN算法的输入为实例的特征向量,对应于特征空间的点;输出为实例的类别,可以取多类。kNN算法假设给定一个训练数据集,其中的实例类别已定。分类时,对新的实例,根据其 k 个最近邻的训练实例的类别,通过多数表决等方式进行预测。因此,k近邻算法不具有显式的学习过程。
kNN算法实际上利用训练数据集对特征向量空间进行划分,并作为其分类的“模型”。 k值的选择、距离度量以及分类决策规则是k近邻算法的三个基本要素。训练数据集的好坏直接决定了KNN模型的好坏。
KNN 原理
KNN 工作原理
- 假设有一个带有标签的样本数据集(训练样本集),其中包含每条数据与所属分类的对应关系。
- 输入没有标签的新数据后,将新数据的每个特征与样本集中数据对应的特征进行比较。
- 计算新数据与样本数据集中每条数据的距离。
- 对求得的所有距离进行排序(从小到大,越小表示越相似)。
- 取前 k (k 一般小于等于 20 )个样本数据对应的分类标签。
- 求 k 个数据中出现次数最多的分类标签作为新数据的分类。
KNN 通俗理解
给定一个训练数据集,对新的输入实例,在训练数据集中找到与该实例最邻近的 k 个实例,这 k 个实例的多数属于某个类,就把该输入实例分为这个类。
KNN 算法特点
优点:
- 精度高
- 对异常值不敏感
- 无数据输入假定
- 超参数少
- 无显式训练过程
- 对于类域交叉的时候,KNN比其他算法效果更好,因为它不是根据类域的划分来进行预测的
缺点:
- 计算复杂度高
- 空间复杂度高
- 对稀有的数据无法正确预测
适用数据范围: 数值型和标称型
在监督学习(supervised learning)的过程中,只需要给定输入样本集,机器就可以从中推演出指定目标变量的可能结果。监督学习相对比较简单,机器只需从输入数据中预测合适的模型,并从中计算出目标变量的结果
监督学习一般使用两种类型的目标变量:标称型和数值型**标称型:**标称型目标变量的结果只在有限目标集中取值,比如真与假(标称型目标变量主要用于分类)
**数值型:**数值型目标变量则可以从无限的数值集合中取值,如0.555,666.666等 (数值型目标变量主要用于回归分析)
SVM和KNN的区别
- KNN根据一个样本点周围的点所属的类别来划分这个样本点的类别,而SVM是在两个类别的边界处,找到一条到所有支持向量的距离最大的分界线。svm通过核函数也可以划分非线性的类别。
- KNN不需要训练,只需要计算,所以数据量大的时候,效率很低,而SVM是需要根据数据来训练出一个最好的分界线。
KNN实战——海伦约会
数据集文件:
数据观察
数据集总共有1000条数据,无缺失值,包含三个特征:
- 每年获得的飞行常客里程数(0—91273)
- 玩视频游戏所耗时间百分比(0.0—20.919349)
- 每周消费的冰淇淋公升数(0.001156—1.695517)
标签包含以下三类:
- 不喜欢的人
- 魅力一般的人
- 极具魅力的人
1 | 0 40920 8.326976 0.953952 largeDoses |
数据可视化
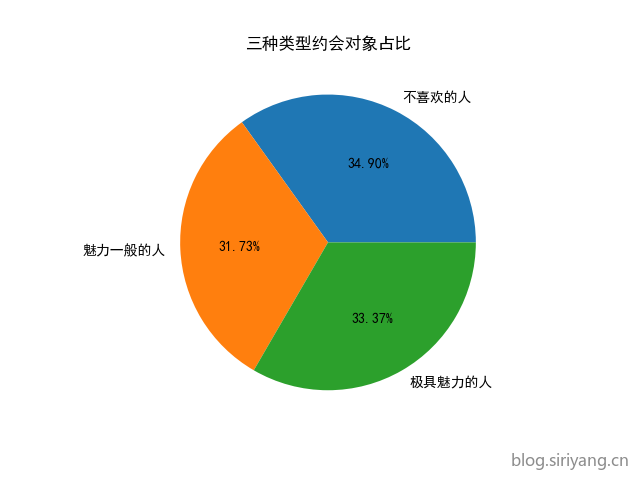
标签占比圆饼图:
1 | plt.title("三种类型约会对象占比") |
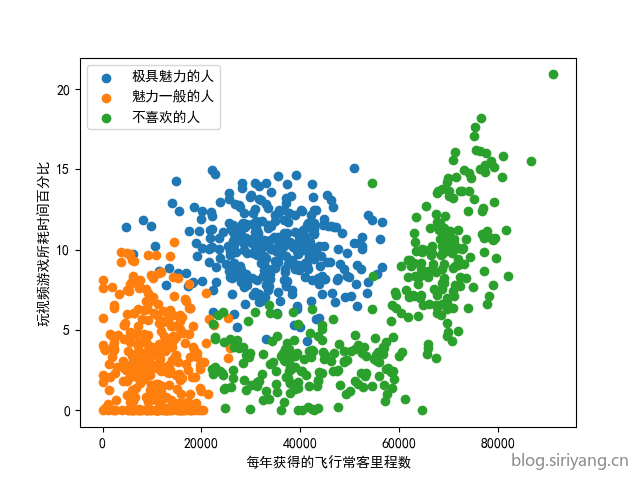
对前两个特征做散点图:
1 | fig = plt.figure() |
数据预处理
- 将标签字段由字符串类型替换为整数
1 | dataset.replace(['largeDoses','smallDoses','didntLike'],[1,2,3],inplace=True) |
- 对特征值进行线性归一化
1 | 0 0.448325 0.398051 0.562334 0.0 |
算法实现
1 | import pandas as pd |
输出结果:
precis is: 0.9575
参考资料

